Analyzing text samples in the NLP Sample application in Pega 7.2.1
After you install the NLP Sample application, you can use the menu to explore text analysis functionality by using default or custom text samples. When the NLP Sample application analysis is complete, you can view the sentiment, category, and entity extraction analysis results of the provided sample.
- Open the NLP Sample portal from Designer Studio by clicking . The portal opens in the browser as a separate tab.
- Select a text analysis model:
- Use example model (Recommended) – Uses the example free text model (FTModels) that is included with the application. With this option, you can analyze the text without configuring your own free text models.
- Select custom model – Uses a custom, free text model rule that you provide.
- In the Applies to field, select the class that the free text model rule applies to.
- In the Free text model field, enter the name of the free text model rule that you want to use for text analysis of the provided sample.
- Provide a text sample to analyze:
- To use a default text sample:
- Click the Input text tab.
- In the Sample text list, select one of the following samples:
- Large sample
- Automobile sample
- Banking sample
- Customer support sample
- Telecom sample
- In the Taxonomy list, select one of the following taxonomies:
- Telecom
- Banking
- Customer support
- Automobile
- To use a custom text sample:
- Clear the Text box.
- Paste your custom text sample into the Text box.
- To import a text sample from an external URL:
- Click the Input URL tab.
- In the URL field, enter the URL of the text sample, for example, an online article. You can use the default URL.
- Expand the Taxonomy drop-down menu, and select a taxonomy to apply to the analyzed sample.
- Click Load Content. The Content field is populated with the text obtained from the URL.
You can edit the imported text.
- To use a default text sample:
- Click Try It to analyze the text sample.
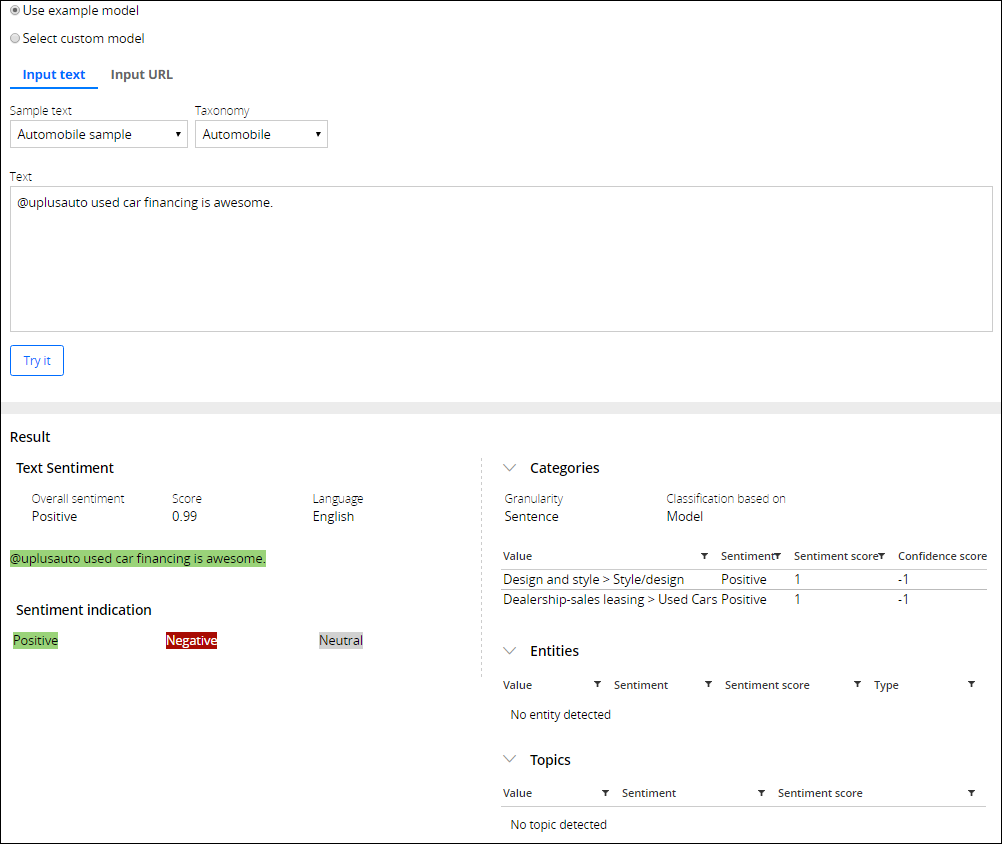
Analyzing text with NLP Sample
- In the Result section, review the results of the text analysis:
- Overall sentiment – The polarity level at the document level (that is, the expressed opinion in the document). The overall sentiment of the document can be positive, neutral, or negative.
- Text Sentiment – The color-coded sentiment analysis at the sentence level. The following highlight colors identify the sentiment of each sentence:
- Green – Positive
- Gray – Neutral
- Red - Negative
- Categories – The predefined assignment of one or more classes or categories to a document or sentence that makes it easier to manage and sort. The categories are defined in the taxonomy that is part of the free text model rule.
- Entities – The keywords identified in the analyzed sample that belong to predefined categories such as names, organizations, locations, or monetary values.
- Topics – Brand names or their synonyms defined in the text analysis model, for example, Apple, iPhone, Samsung.
- Features – The terms that are implicitly detected by the free text model as the main point. In the sentence "I am not fond of their webpage as I cannot find anything there," the feature is the term webpage.
You have analyzed various types of text samples to become familiar with the text analytics functionality provided by the Pega 7 Platform through the NLP Sample application. To continue to advanced analysis of text-based content from social media, configure the rules that support text analytics of Facebook posts, Twitter tweets, or metadata of YouTube videos.
Next step: Creating rules that support text analysis of social media data.