Best practices for Stream service configuration
Follow these guidelines for the recommended deployment configuration.
Expected throughput
Data throughput depends on the number of nodes, CPUs, and partitions, as well as the replication factor and bandwidth.
Review the results of tests on three running stream service nodes on machines with the following configuration:
- CPU cores: 2
- Memory (GB): 8
- Bandwidth (Mbps): 450
- Number of partitions: 20
- Replication factor: 2
The following table shows the test results for writing messages to the stream (producer):
| Records | Record size (bytes) | Threads | Throughput (rec/sec) | Average latency (ms) | MB/sec |
|---|---|---|---|---|---|
| 5000000 | 100 | 1 | 83675 | 2.2 | 8.4 |
| 5 | 172276.1 | 11.9 | 17.2 | ||
| 10 | 216682.8 | 40.4 | 21.7 | ||
| 100 | 1 | 32967.7 | 5.1 | 33 | |
| 5 | 53033.7 | 48.6 | 53 | ||
| 10 | 49861.7 | 174.3 | 49.8 | ||
| 100 | 1 | 76812.1 | 2.4 | 7.7 | |
| 5 | 165317.4 | 13.3 | 16.5 | ||
| 10 | 203216.3 | 46.1 | 19.38 | ||
| 1000 | 1 | 35865.7 | 4.8 | 35.9 | |
| 5 | 52456.7 | 41.9 | 52.4 | ||
| 10 | 50266.1 | 158.8 | 50.3 |
Producer throughput - test results
The following table presents the test results for reading messages from the stream (consumer):
| Records | Record size (bytes) | Threads | Throughput (rec/sec) | MB/sec |
|---|---|---|---|---|
| 5000000 | 100 | 1 | 120673.8 | 12 |
| 5 | 150465 | 15 | ||
| 10 | 143395.3 | 14.3 | ||
| 1000 | 1 | 54128.4 | 54.1 | |
| 5 | 55903.3 | 55.9 | ||
| 10 | 54674.5 | 54.7 |
Consumer throughput - test results
Disk space requirements
By default, the Kafka cluster stores data for seven days. You can change that time by overriding the log.retention.hours property.
Example:
Your goal is to process 100,000 messages per second, 500 bytes each, and to keep messages on the disk for one day. The replication factor is set to 2.
The expected throughput is 50MB/sec:
- 3GB is used in one minute for a single copy of the data.
- 6GB of disk space is used in one minute due to the replication factor of 2.
- The total throughput is 360GB in one hour and 8.64TB in one day.
- Apart from your data, the Kafka cluster uses additional disk space for internal data (around 10% of the data size).
In that sample scenario, the total minimal disk size should be 9.5TB.
Compression
Depending on your needs, you can choose data compression using one of the algorithms that Kafka supports: GZIP, Snappy, or LZ4. Consider the following aspects:
- GZIP requires less bandwidth and disk space, but this algorithm might not saturate your network while the maximum throughput is reached.
- Snappy is much faster than GZIP, but the compression ratio is low, which means that throughput might be limited when the maximum network capacity is reached.
- LZ4 maximizes the performance.
Review the following table and diagram with throughput and bandwidth usage per codec:
| Codec | Throughput % | Bandwidth % |
|---|---|---|
| none | 100 | 100 |
| gzip | 147.5 | 5.2 |
| snappy | 116.3 | 64.1 |
| lz4 | 188.9 | 34.5 |
Throughput and bandwidth per codec (%)
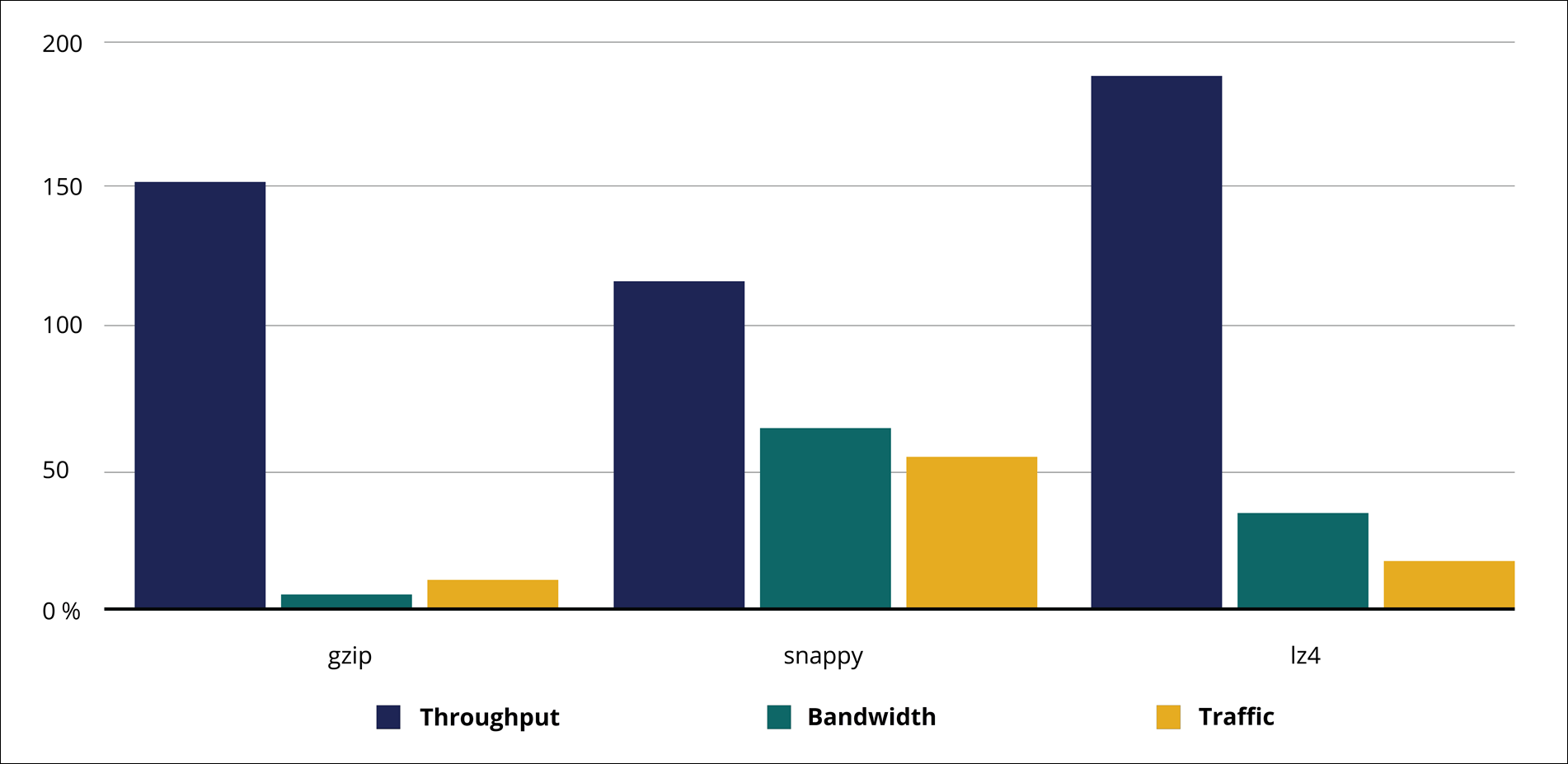
Throughput and bandwidth metrics per codec (%)
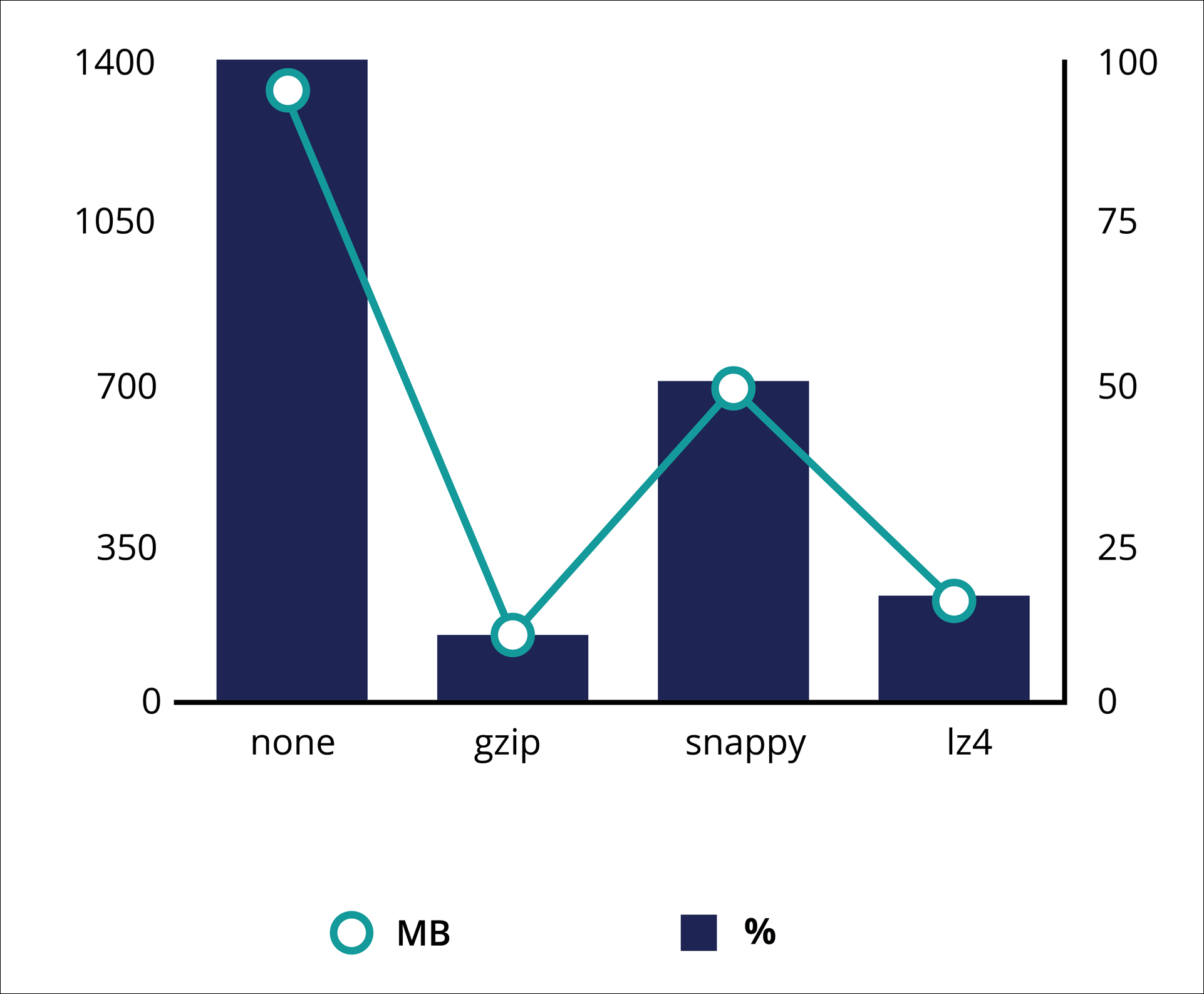
Disk usage metrics per codec
To define the compression algorithm, update the compression.type property. By default, no compression is applied.
Data folder
By default, the stream service keeps its data in the current working directory. For Apache Tomcat, the working directory is located in: <your_tomcat_folder>/kafka-data
Ensure that you set up that path to the location with enough disk space.
To view the main outline for this article, see Kafka as a streaming service.
Previous topic Kafka as a streaming service Next topic Communication between embedded Kafka and Pega Platform