Big data enhancements in decision management
Pega 7.2.1 provides multiple enhancements to big data capabilities in decision management. You can create external data flow rule instances and run them outside of the Pega 7 Platform. This solution utilizes the infrastructure of external systems to process large amounts of data and improves the performance of the Pega 7 Platform by decreasing the data transfer between external data sets and the Pega 7 Platform. Additionally, you can connect to Hadoop Distributed File System (HDFS) data sets that store data in the Apache Parquet file format.
External data flow
With the external data flow (EDF) rule type, you can utilize the Hadoop infrastructure to run predictive models directly on an external HDFS data set and write results to the external data flow destination.
Similar to how you configure the data flow rule type, you can configure external data flow rules on a graphical canvas where you apply processing instructions in the form of shapes and connectors. On the external data flow rule canvas, you can place Source, Predictive Model, Filter, Merge, Convert, and Destination shapes.
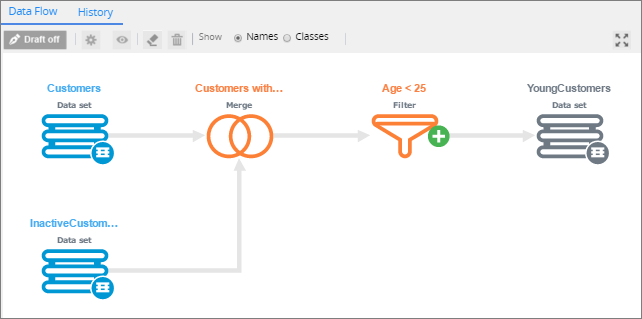
External data flow rule canvas
When an external data flow rule instance is started from the Pega 7 Platform, an external data flow run process is created. The external data flow translates the processing instructions into MapReduce jobs that start a YARN ResourceManager application in the Hadoop infrastructure for data processing. When the external data flow run finishes, the results are written to a destination and all resources that were applied to the external data set are removed.
HDFS data set support for the Apache Parquet file format
From the Pega 7 Platform, you can access an HDFS data set that stores data in Apache Parquet files and perform various operations on that data set. This file format is available to any project in the Hadoop environment for all data processing frameworks, data models, or programming languages.
File system configuration
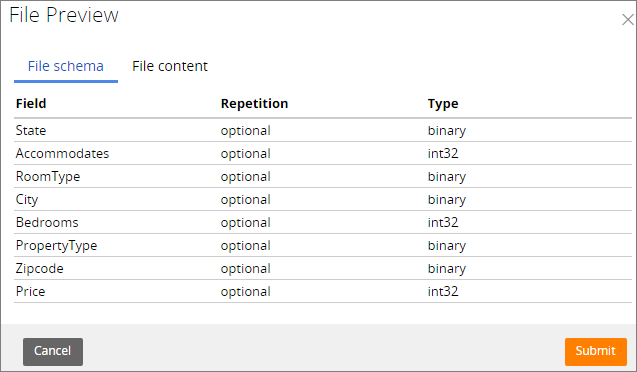
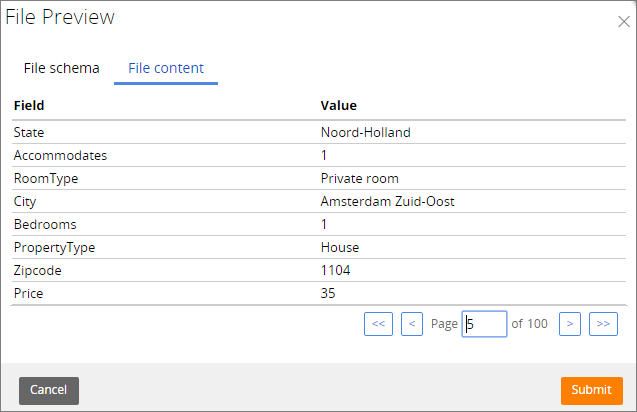
On the Pega 7 Platform, you can preview the content of the HDFS data set that stores data in a Parquet file. The preview window consists of two sections:
- File schema - Displays the structure of the file (field names, repetition pattern, and field types)
- File content - Displays the first 100 records in the file
File format
You can select Parquet as the file type for the HDFS data set. You can also select a compression codec (Snappy or gzip) for data set write operations.
Property mapping
For the Parquet files, property auto-mapping is used by default. Additionally, you can generate properties from the Parquet file that do not exist in the Pega 7 Platform.
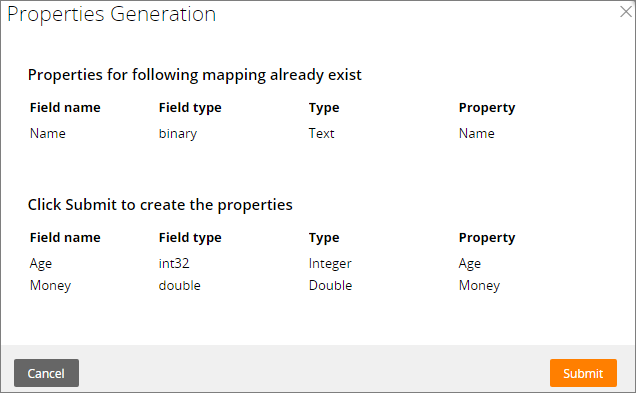
Generating properties from the Parquet file on the Pega 7 Platform
Supported data set operations
You can perform the following types of operations on a Parquet file from the Pega 7 Platform:
- Browse - Returns the selected records from the data set
- Save - Saves the selected records to the file by using the selected compression method
- Truncate - Removes all records from the defined file path
Previous topic Introduction to big data capabilities on the Pega 7 Platform Next topic Big data functionality enhancements