Customizing the data import wizard by adding fields and logic
You can customize the data import wizard to add new fields and logic during data import. You can also define a default unique field mapping for data import, skip key validation, and customize data import for a data type.
Skipping key validation
When you import a .csv file, you need to validate the key field in the imported .csv file by mapping it to the field in your data type that acts as a unique identifier. This mapping is not possible in all cases. Beginning with Pega 7.2.2, you can skip key validation during the data import process. This feature is useful when you import records without keys and expect to generate keys during the import process by using custom APIs in the preprocess extension point.
- Override the pyPreProcessDataImport activity.
- Set the pySkipKeyValidation property to true.
 Disabling key validation
Disabling key validation
When you set the value for the property to true, the key field is not validated during the data import process.
Adding fields for customizing data import
You can add fields to customize data import for a new import purpose. For example, you can add a New location field as shown in the following figure:
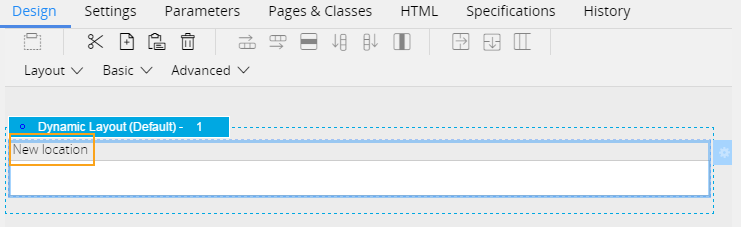
New field for data import
- Override the pyCustomConfiguration section to add new fields.
The New location field is displayed in the Import records step of the data import process. You can enter a value for this field (for example, New York) at run time:
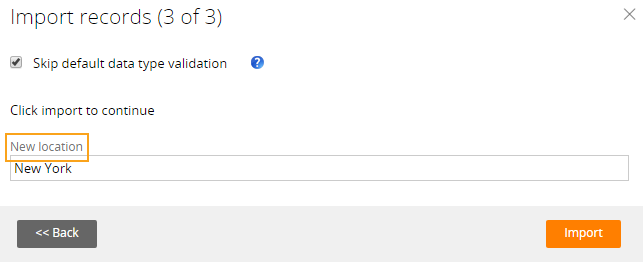
New field at run time
The activity that defines the logic for data import can access the work object that contains this field. If you want to collect new information, add fields to the work object class, and not to some other top-level page.
Adding logic for data import
You can define the logic for the data import that corresponds to new and existing purposes and fields.
- You must define the logic for data import if you have added a new purpose.
- The import wizard does not call the pyCustomPostProcessing activity for the Delete import purpose.
- You cannot use custom post-processing for an add-only import of a class that does not have a BLOB and that uses autogenerated keys.
- Override the pyCustomPostProcessing activity.
- Provide the parameters on the Parameters tab of the activity:
- Purpose – The new data import purpose.
- UniqueFieldsList – A list of HashStringMap objects. The list contains the unique field and value pairs in the imported .csv file. You can create and use a page for each pair in this activity.
- ListSize – The number of values for the uniquely mapped field in the imported .csv file.
You can use these variables as input parameters for the activity.
For example, you can do the following actions:
- Use a loop to iterate through the list of values for the uniquely mapped field in the imported .csv file, as shown in the following figure:
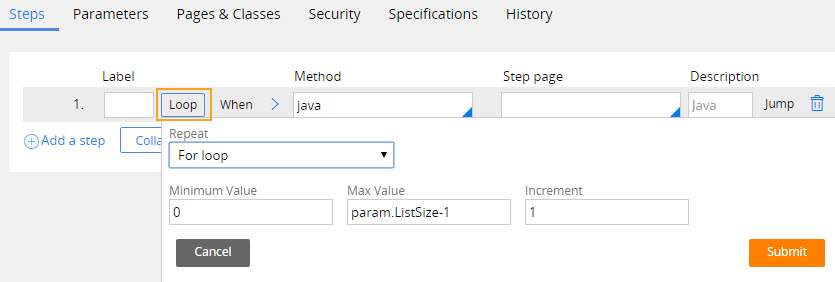
- Use the function @Utilities.pxGetKeyPageFromList(param.UniqueFieldsList,param.pyForEachCount) to get the page from the list at the current index. This function returns a clipboard page that you can use in the activity.
The import wizard calls this activity when you click in the Import records step of the data import process.
For example, if you override this activity to update all the locations of your Employee data type to a common location such as New York, the data type is updated as shown in the following figure:
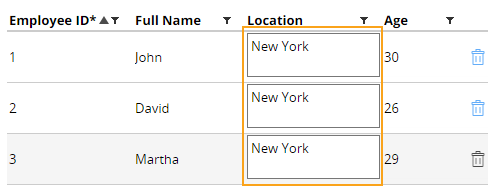
Locations updated after calling the activity
Defining a default unique field mapping for data import
Beginning with Pega 7.2.2, you can define a default mapping between the fields in the .csv file and the fields in your data type that act as a unique identifier (key). This default mapping saves time during the import process. For example, if you import data for your Employee data type on a regular basis, you can define a default mapping between the Staff ID field in the .csv file and Employee ID field in your data type.
- Override the pyCustomUniqueSourceFieldMapping activity.
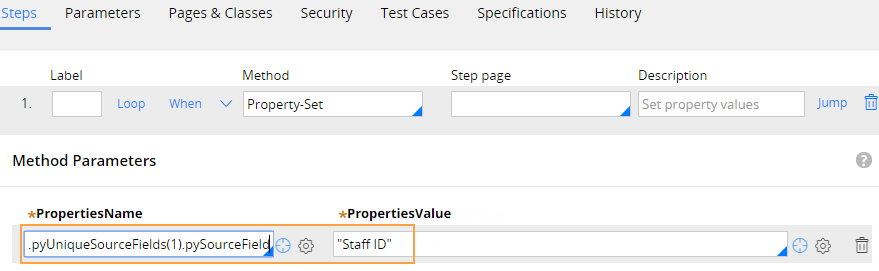
Defining a default field mapping for data import
In the Map fields step of the data import process, the system sets the default value of the Match existing records by field to the value that you used in the activity (Staff ID) and marks the mapped field in your data type (Employee ID) as a record identifier:
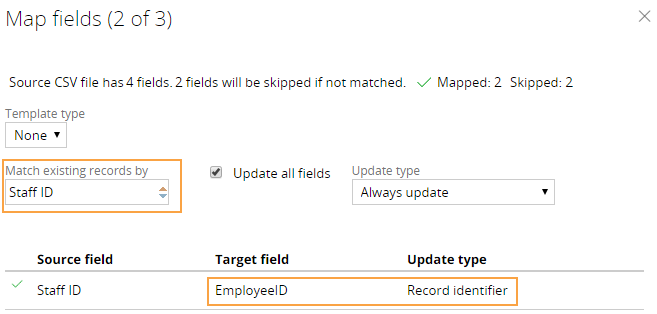
Default field mapping at run time