Partition keys in Stream Data Set rules
Beginning with Pega7.3, you can define a set of partition keys when you create a Data Set rule of type Stream. Setting partition keys in a data set is useful for analyzing data across multiple nodes and helps you ensure that all related records are grouped together.
Setting the production level in an application
You can use the properties defined in the Applies To class of the Data Set rule as partition keys. Additionally, if the Data Flow rule (for which the stream data set is the source) references an Event Strategy rule, you can define only a single partition key. That partition key must be the same as the event key that you defined in the Real-time Data shape on the Event Strategy form.
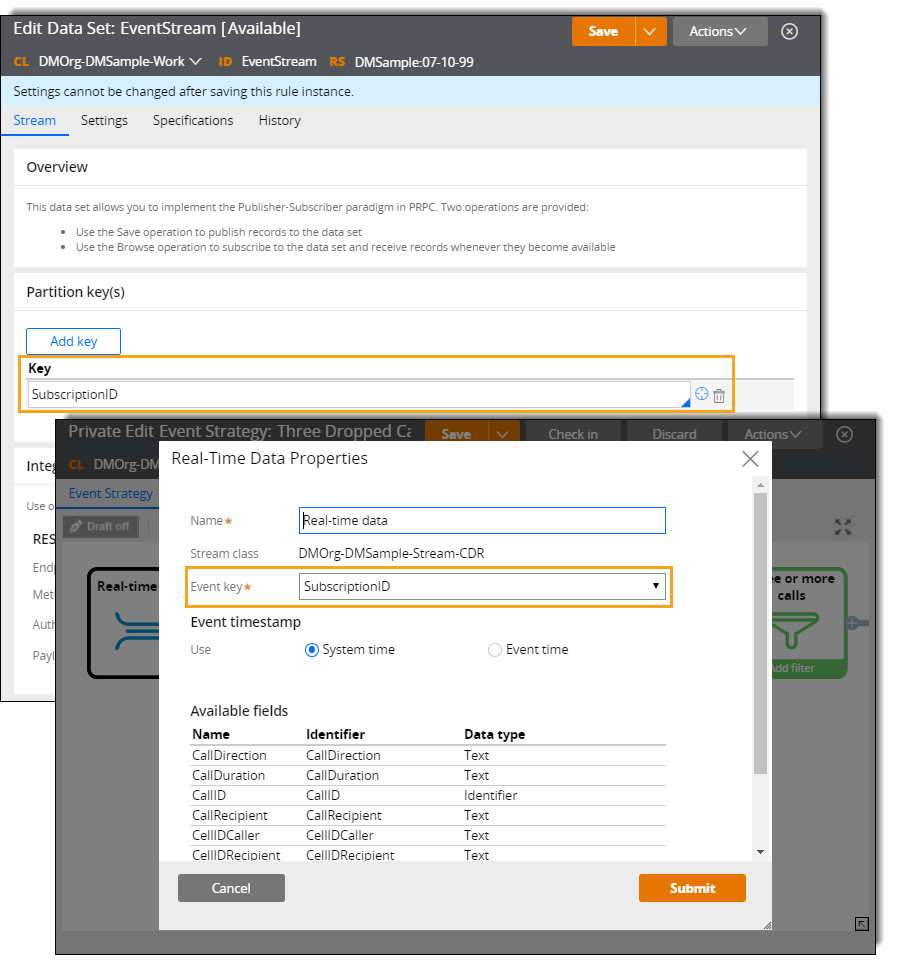
Defining partition keys for an event stream
Active data flows that reference stream data sets that have at least one partition key defined continue processing when the node topology changes, for example, if a node fails or a node is removed from the cluster. Such a data flow adjusts to the change in the number of Data Flow service nodes, but the data that was not yet processed on the failed or disconnected node is lost.
For more information, see Defining partition keys for stream data sets.