Big data functionality enhancements
Pega Platform™ features maintenance improvements to the Hadoop host configuration, HBase data set, and HDFS data set. System architects can more easily make the Apache Hadoop File System (HDFS) and HBase storages available to business scientists for exploratory analysis and predictive model building.
HBase data set
The HBase data set is designed to read and save data from an external Apache HBase storage. Enhancements to this data set allow you to:
Do the mapping between the HBase storage and the HBase data set without any connector reference.
Map a column family to a Page Group or a Page List.
Use a validation mechanism for the mapped property and the column family.

An instance of the HBase data set rule
Use more complex property types in the HBase data set to support flexible data structure of the Apache HBase storage.
Use the option to see data inside the Apache HBase storage.
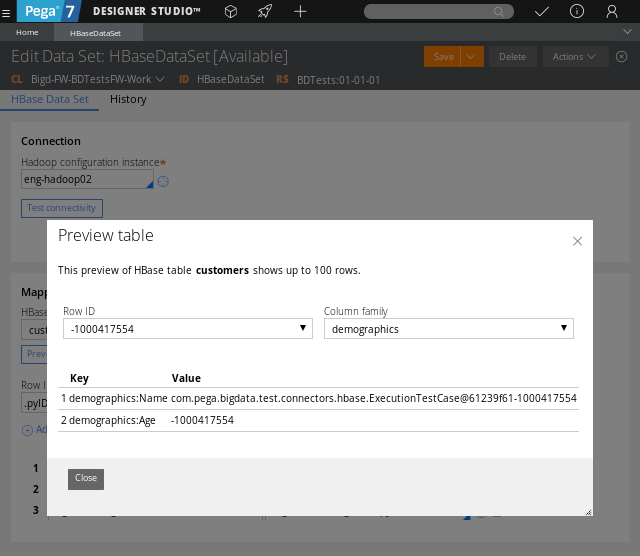
The Preview option for the HBase data set
HDFS data set
The HDFS data set is designed to read and save data from an external Apache Hadoop File System (HDFS) storage. Enhancements to this data set allow you to:
Use the HDFS data set to consume outputs of the Map-Reduce job.
Use the File system configuration option to look for files with a given pattern.
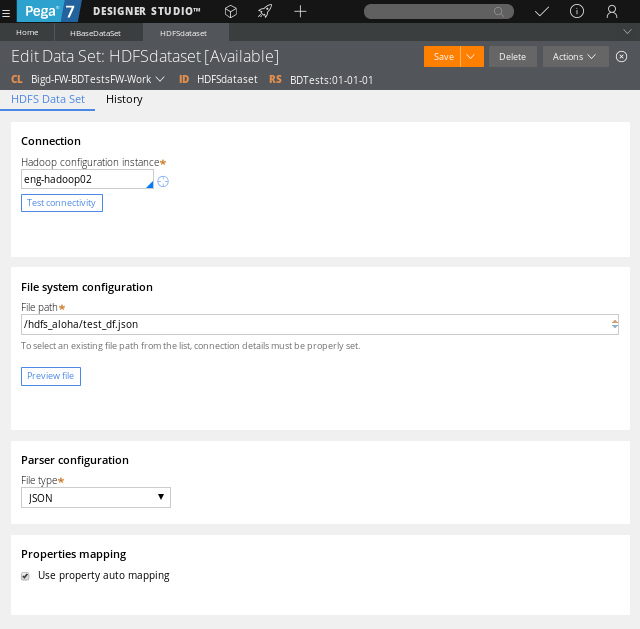
An instance of the HDFS data set rule
Hadoop host configuration
Hadoop data instances allow you to define connection details for the Hadoop host, including connection details for datasets and connectors. Enhancements to the Hadoop record allow you to :
Do an optional NameNode host configuration for the HDFS connection on the Hadoop host configuration.
Do an optional Zookeeper host configuration for the HBase connection on the Hadoop host configuration.

An instance of the Hadoop host with configured connection for HDFS and HBase
Previous topic Big data enhancements in decision management Next topic Defining Hadoop records