Managing big data to make informed business decisions
Create big data sets and configure a Hadoop connection to process high-volume and complex data on Pega Platform™. Move data between the Apache Hadoop cluster and Pega Platform by performing read-write operations on data sets.
You can work with big data and external environments by using the following Pega Platform tools:
- Hadoop records that configure a connection with an Apache Hadoop cluster.
- HBase and HDFS data sets that connect to an external system so that you can perform read-write operations on high-volume data.
- Monte Carlo data set that you can use to generate synthetic and realistic data for simulations.
- External data flows that process data on an external environment.
Apache Cassandra
You can create Decision Data Store (DDS) data sets in Pega Platform to store your data in an internal Cassandra storage that is part of the platform. The Cassandra storage is a structured and distributed database that is scalable, highly available, and designed to manage very large amounts of data. If you already store your data in an external Cassandra cluster, you can integrate it with Pega Platform by creating Connect Cassandra rules.
- Techniques for integrating Cassandra with your application
- Creating a Decision Data Store data set
- About Connect Cassandra rules
- Integration services
Apache Hadoop
Pega Platform provides access to data that is stored on an external Apache Hadoop cluster. You can read and write data from either an Apache HBase big data store or Hadoop Distributed File System (HDFS) by using the appropriate data sets. You define connection details for the Hadoop host and configure the connection setting for HBase and HDFS data sets by using Hadoop records.
Monte Carlo data set
You can test the strategies or data flows in your application in the absence of real data by using a special Monte Carlo data set that generates random realistic-looking data. Create a Monte Carlo data set that you can use later as a source in Data Flow rules and run simulations.
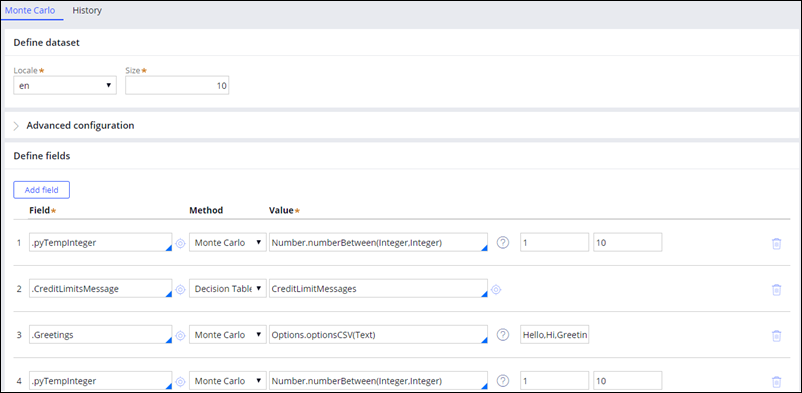
Creating a Monte Carlo data set
HBase data set
You can retrieve data that is in a high-volume data source or save a large number of records to it by connecting to the external Apache HBase big data store. Create an HBase data set that is specifically designed for this purpose and that you can use later in Data Flow rules as either a source or destination.
- HDFS and HBase client and server versions supported by Pega Platform
- Creating an HBase data set record
- Tutorial: Working with HBase data sets on the Pega 7 Platform
HDFS data set
You can retrieve data that is in a high-volume data source or save a large number of records to it by connecting to the Apache Hadoop Distributed File System (HDFS). Create an HDFS data set that is specifically designed for this purpose and that you can use later in Data Flow rules as either a source or destination.
- HDFS and HBase client and server versions supported by Pega Platform
- Creating an HDFS data set record
- Tutorial: Working with HDFS data sets on the Pega 7 Platform
Kafka
Apache Kafka is a fault-tolerant and scalable platform that you can use as a data source for real-time analysis of customer records (such as messages, calls, and so on) as they occur. The most efficient way of using Kafka data sets in your application is through Data Flow rules that include event strategies. Create a Kafka data set that you can use later as a source in Data Flow rules and run simulations.
- Kafka data sets in decision management
- Creating a Kafka configuration instance
- Creating a Kafka data set
File data set
You can access and process data set that are stored in CSV and JSON files.
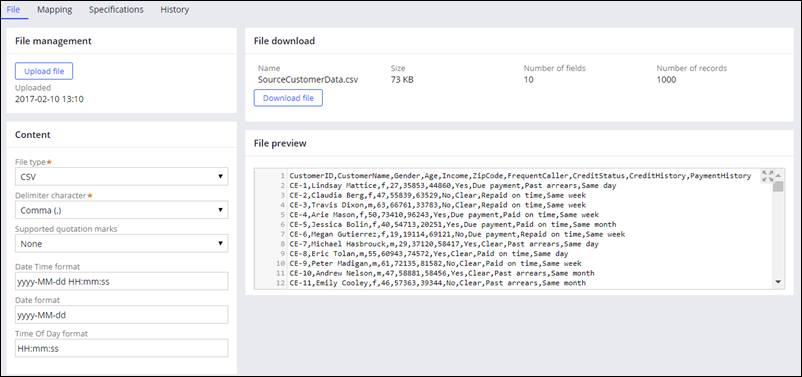
Creating a File data set
External data flows
You can run predictive analytics models and process high-volume data without overloading the data transfer between the Apache Hadoop cluster and Pega Platform, using external data flows that run on an external system. Create an external data flow that can have only an HDFS data set as a source and destination.
Previous topic Default fact properties in Pega 7.2 to 7.3 Next topic Introduction to big data capabilities on the Pega 7 Platform