Importing large amounts of data by using the data import File Listener
When you need to import large volumes of data (millions of rows), use the data import File Listener instead of the data import wizard. The data import File Listener uses multithreading for faster throughput, while the wizard uses single-thread processing.
Pega Sales Automation includes a File Listener for the following entities:
- Operator
- Contact
- Household
- Lead (individual and business)
- Opportunity (individual and business)
- Organization
- Task
- Customer activity
- Territory
- Account
File Listener import recommendations
For best performance while using the data import File Listener, keep the following recommendations in mind:
- Before beginning to import all of your records, import a few to start with and fix any issues that occur.
- The size of the File Listener base upload should not exceed 1 million records in a single file.
- The recommended number of records for batch uploads is 1,000 records. You can set this figure in .
- To improve performance by disabling creation of an audit history, use Add Only mode for the initial data import.
- To ensure maximum parallel processing, there must be as many input files for the file listener as there are threads, because each thread processes only one file at a time. You can set the number of X thread in the File Listener properties in Dev Studio, in the Listener properties section.
- In a PostgreSQL single-tenant system, unique ID generation is highly efficient in a high-volume import process. Work item IDs are generated in batches, and you can set the batch size with the idGenerator/defaultBatchSize dynamic system setting. For more information, see Increased performance for work ID generation.
- In non-PostgreSQL multi-tenant systems, high-volume import process should not include generating unique IDs. Instead, you can save time by including pyID for work object records in the CSV import file to skip calling the GenerateID activity. After the import of contacts is complete, update the unique ID stored in the data-uniqueID database table. Set the Table name value in the data-uniqueID database table to the last imported pyID record in the contact table.
- Database indexes improve query performance. However, when you update a large database table, the system performs reindexing, which can cause lower performance. Remove non-essential indexes during the import phase. After the import is complete, re-enable indexing.
Preparing the data
The data import File Listener uses the same underlying APIs as the data import wizard to process files located in predetermined folders on the server. Importing data by using the data import File Listener requires the use of templates. As a best practice, use the data import wizard to make any template changes prior to using the file listener to import any data. For more information, see Preparing the data and Pega Sales Automation sample data templates.
Configuring the File Listener data import for on-premises environments
Before running a data import by using File Listener, you must configure the data import settings.
- In the navigation pane of
App Studio, click .
- Optional: To modify the default template and purpose configuration, in the navigation pane of Dev Studio, click App, and then search for and open the Resource Settings data transform.
By default, the system configures the data import File Listener with SA_<name of objects> as a template and Add or update as a purpose. - On the Features tab, in the File Listener Configurations section, enter the path to the root folder in the File Listener source location, and the email address to which you want to send notifications.
- Optional: To disable creating an audit history and to improve performance, in the
File Listener Configurations section, select the
Initial Data Migration check box.
- Click Save.
- Optional: If you want to modify the default template and purpose configuration, in the
Dev Studio navigation pane, click App, and then search
for and open the ResourceSettings data transform.
Resource settings example configuration 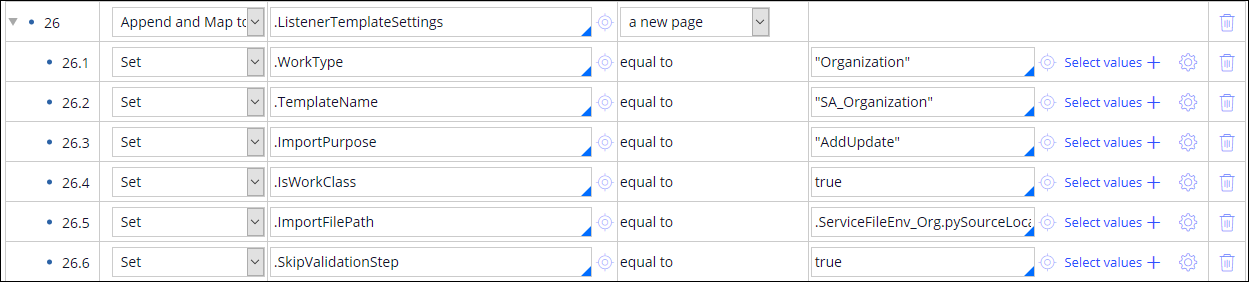
Configuring the File Listener data import for Pega Cloud
Before running a data import by using File Listener, you must configure the data import settings.
- In the navigation pane of
App Studio, click .
- In the header of Dev Studio, search for and select the storage/class/defaultstore:/type dynamic system setting (DSS).
- In the Value field, enter filesystem.
- Click Save.
- In the header of Dev Studio, search for and select the FileListenerSourceLocation dynamic system setting.
- In the Value field, enter the root folder in the File Listener source location.
- Click Save.
Running the File Listener data import
After you configure the data import settings, run File Listener to import large volumes of data.
- In the navigation pane of Dev Studio, click , and then open the listener that you want to run.
- In the Listener nodes section, clear the Block startup check box.
- In the Source properties section, enter the source file
format. File Listener only supports csv and txt files.
- Click Save.
- In the header of Dev Studio, click the Switch Studio menu, and then click Admin Studio.
- In the navigation pane of Admin Studio, click , and then open the listener that you configured.
- In the Requestor login section, enter your user name and password.
Previous topic Improving data import performance by using configuration templates Next topic Data import rules and extension points