Interpreting the Performance Tool (PAL) Detail display
After the PAL data has been collected for an application, it is necessary to analyze the information. Process Commander gives the application developer a number of performance tools for this analysis.
- the PAL Detail display (see Interpreting the Performance Tool (PAL) Detail display)
- DB Trace (see Using the DB Trace and Profiler tools to understand performance)
- Profiler (described in detail in the article Using the DB Trace and Profiler tools to understand performance)
This section begins with an overview of the factors that affect an application’s performance; the linked articles describe the tools in detail.
IMPORTANT: In Version 5.3, PAL timer values are “mutually exclusive.” Prior to V5.3, when (for example) a declarative network was built to run a Declare Expression, the Elapsed Time Executing Declarative Rules might be higher than the Total Request Time, due to the fact that the former included other processing that was also occurring, such as Rule I/O, Other I/O, etc.; the Declarative timer was counting time that was also counted in another timer.
Beginning in Version 5.3, if one timer is going and another is triggered, the first timer stops (temporarily so that the time is not double-counted. In the above example, if the Rule I/O timer starts, the Executing Declarative timer stops until the Rule I/O processing is finished, and then continue tracking the Declarative processing.
NOTE: The only exception to the “mutually exclusive” setup is Total Request Time, which accumulated no matter what other timers are running.
Quick Links
Suggested Approach
Follow these steps to gather and analyze performance with PAL:
- Take PAL readings (as described in the first section of this article).
- Look at the Total CPU number to determine whether it is a high, medium, or low value.
- Compare Total CPU to Total Elapsed to see where to begin the investigation.
- If Total CPU is high:
A. Review the specific CPU numbers available in the CPU section to determine where the CPU time was spent (by percentage).
1. If one reading dominates the group (62% of the Total CPU time was spent retrieving Rule database lists, for example), then investigate that area of the application.
B. If the specific CPU readings are inconclusive, move on to the Rule Execution counts, and see if one number stands out there.
C. Check Database Access and/or Requestor Summary readings.
- If Total CPU is a mid-level value, compare to Total Elapsed to see if that value is high or low.
- If Total CPU is low, then that part of the system is fine – go on to check Total Elapsed.
- If Total Elapsed is high:
A. Review the specific Elapsed numbers available in the Elapsed section to determine where the elapsed time was spent (by percentage).
1. If one reading dominates the group (62% of the Total Elapsed time was spent retrieving rule-resolved rules from the database, for example), then investigate that area of the application.
B. If the specific Elapsed readings are inconclusive, move on to the Rule Execution counts, and see if one number stands out there.
C. Check readings in the additional sections:
- database access
- requestor summary
- parsing statistics
- connects statistics
- services statistics
Detail Display
Click the name of the INIT, DELTA, or FULL type of readings to display the detail window of the data for that reading.



Using PAL to understand Response Time
As stated in a prior section, response time is the time it takes for the system to return from a processing step (saving a work object to the database, opening a New Work object). There are several factors which make up response time:
Network time – includes time spent:
- sending data to and from the browser
- sending data to and from the database or other external resource
- interactions between the systems
Response time from databases or other external resources – includes:
- time spent waiting for responses from other resources
- frequency of access to the other resources
CPU time – includes time spent on:
- application/business processing
- Rule Resolution
- looking up and invoking declarative rules
Rules Assembly time – includes time spent on:
- assembling the rules
- database I/O – looking up rules not currently in the cache
- Java compilation time
Troubleshooting Process
To pinpoint whether a performance issue is due to a slow (rather than the application), use the following process:
1. Measure the response time for an item, and compare against Total Elapsed.
This can be measured either manually by the user or by the user’s test tool. Compare that number against the Total Elapsed PAL reading. Elapsed time measures the time spent processing inside the Process Commander application to fulfill the request. The total elapsed time is the time the server (the JVM) required to complete a transaction. NOTE: This number is impacted by other threads running in the JVM (including garbage collection).
2. Determine whether the problem is with the network.
If the user-measured response and the Total Elapsed times are compared and are reasonably close, this means that the network latency and the time spent sending data across the network are minimal – the time the user sees the system spending is being spent processing inside the application. At this point, further investigation in the application itself is indicated.
However, if these two times are substantially different, then the network is impacting the response time. If a problem is indicated here, then more work must be done to isolate where in the network the problem is occurring.
3. If the network is impacting response time, determine whether it is the network or the browser.
The problem might be with the network itself, or it might be with the browser trying to execute JavaScript to display data. Test tools can be used to execute work objects without running the JavaScript, which would remove the second part of that equation. If there is still a problem, the network is where the slowdown occurs. If the problem disappears when the JavaScript is not run, then it is necessary to look further into the data displays.
4. Research possible network issues.
There could be two different issues with the network itself:
- the network is slow
- Process Commander is overloading the network by trying to move too much data
To determine which issue is occurring, look at whether the network is “saturated” with sending data: the number of bytes being sent across the network, divided by interaction (in other words, how many bytes, on average, would be in a single request). Use:
- Number of Input Bytes received by the server
- Number of Output Bytes sent from the server
These readings will give the developer an idea of whether there is too much data being sent across the network by Process Commander, or whether the network itself is having problems.
Once the issue is isolated to the application, the PAL detail screen can be used to further pinpoint the problem.
Top of page
Interpreting PAL Detail Readings
The first PAL screen shows a number of summary readings. Some of these are the same as the detail readings; other numbers are summed from several of the detail stats. This summary section is then repeated at the top of the detail display.

Analysis of the application’s performance should start with the Detail readings behind these Summary statistics:
- As described in the first section of this document, take PAL readings of the business process to be reviewed.
- After running the process, click the FULL or DELTA reading to look at the Detail display.
- On the Detail display, begin the analysis by comparing Total CPU and Total Elapsed. A quick review can point the developer to the appropriate section for more detailed investigation. If the CPU numbers seem reasonable, but the Elapsed time is high, then begin by looking at Elapsed. If both Elapsed and CPU time look high, begin with Total CPU.
Total CPU Time
CPU readings are not tracked for systems running on UNIX platforms, as such tracking is too resource-expensive.
For systems where CPU is tracked, start with the Total CPU number. On the Detail screen, Total CPU time for the reading(s) is the time, in seconds, that the Process Commander server CPU spent processing the current action. CPU readings are very important to performance analysis.
For an application with a suspected CPU issue, the Total CPU should be measured first for one screen. After displaying the PAL Summary display (to establish the baseline), open a work object to display the first screen; click Add Reading in PAL. The DELTA line should give the Total CPU required for this first screen.
Based on whether the Total CPU reading is High, Medium, or Low, different analysis paths may be chosen.
CPU Reading
Description
High
A CPU reading is considered high if it was over a half-second per screen.
Medium
Between .2 and .5 seconds per screen.
Low
Under .2 seconds per screen.
Important notes about CPU:
- A “CPU second” means that the CPU is at 100% capacity for that user for that second. If more than one user hits that point in the process at the same time as the first user, then the second user will have to wait until there is CPU capacity for their processing.
- The above measurements are average numbers, to give application developers guidelines on where they should spend their time reviewing the performance of the application. Note that the above numbers are weighted and based on the CPU speed of the Process Commander server being used. Process Commander uses a 2GHz Intel Pentium server as its reference for the above CPU numbers; customers should adjust these numbers up or down based on their production server CPU speed.
- These CPU numbers may change depending upon the type of application being run. For a low-volume, complex application with lots of processing, the values for low, medium, or high CPU usage should be higher. For a high-volume application with simple screens, the CPU usage numbers might be lower. For example, if a process formerly taking three hours is automated onto one screen, and that screen takes five seconds to process, although that might seem like a very high CPU reading, that is still a huge time savings for the company in terms of overall process, and would be considered appropriate performance. The same five-second CPU time for a high-volume call-center application would be completely unacceptable.
High Total CPU Reading
There are a number of reasons that an application might have a high CPU reading. These reasons include:
1. Excessive I/O to databases
An application may be requesting a list of a thousand rows from a table in the database; not only does the system have to extract this large amount of information from the database, but then all the objects must be created to store this information on the Clipboard in order to use the information. If only one or two entries in this huge list are actually required, these queries can be exceedingly inefficient.
If the developer believes this might be happening, the Database Access counters can indicate the amount of data being requested from the database.
2. Improper Use of Clipboard
On the clipboard, are items being reused, or are they being newly created each time, and then destroyed after use? Every item that is created and then removed must be managed (object creation and garbage collection), using up resources.
3. Rules Assembly
If the PAL readings were done the first time that a process is run in the system, the Rules Assembly numbers may be very high (as the Rules Assembly is done on the first use of most Rules). Run the process a second time, and if the Total CPU process is much lower, this was in all probability a Rules Assembly problem.
If this is the second or third time that the same process is being run by the same user, and Rules Assembly readings are still present, there may be other problems with the system. Check the caching sizes for the system – they may be too small to hold the number of rules being Rules Assembled (which causes them to have to be re-assembled each time).
4. Complex or Excessive HTML
The business processes build HTML for the user interface. These HTML screens could range from being very simple to quite complex, with many different sections all having to be processed every time the screen is updated. If all of the processing is on one screen, then everything on that screen must be processed every time one change is made. Breaking up the display among several screens can help prevent excessive unnecessary processing.
5. Inappropriate use of Declarative Rules
Declarative Expressions may be set to run whenever any of their properties are changed. If the Target Properties aren’t needed for every transaction, it may be more efficient to set the Expressions to calculate when they are used (“Whenever Used”), to prevent unnecessary calculation of the Expressions.
6. Too Many Rules Executed
It is possible to create interactions where the system must work through thousands and thousands of Rules (rules may be run repetitively, or the process may loop). This could cause a performance slowdown.
To determine where the problem of high CPU originates, look at the CPU Time Detail section of the Detail screen:
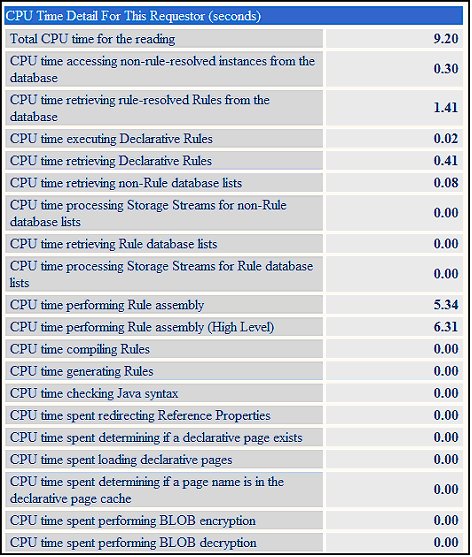
NOTE: Some of these readings may contain no data.
Add up all the CPU counters, and subtract that number from the Total CPU Time reading. The difference between the sum and the Total CPU is directly related to the processing of the application. The direct actions of querying the database and getting the Rules ready for execution is tracked by the PAL readings; the actual application processing is not, as it is different for every customer.
If any of the counters are a high percentage of the total, that needs to be investigated.
Example:
From the above example, a DELTA reading was taken after a Work object was processed. This delta reading shows that Total CPU was 9.2 seconds.
CPU PAL Reading
Value (seconds)
Percent of Total
Total CPU
9.20
100%
accessing non-rule-resolved instances from the database
.30
3.26%
retrieving rule-resolved Rules from the database
1.41
15.32%
executing Declarative Rules
.02
.21%
retrieving Declarative Rules
.41
4.45%
performing Rules Assembly
5.34
58%
In the above example, CPU time performing Rules Assembly is taking almost half the Total CPU; thus, it may be that the Rules Assembly process was being executed here, and another reading of the same process may result in lower readings.
If looking at the individual CPU readings is inconclusive (they are all low, or they are about the same percentage and none stands out), then the number counters should be investigated. Counters fall into several groups:
- Rule execution counters
- Database access counters
- Clipboard Page numbers
Check each one to see where the volume of the processing is, to determine whether there is an isolated problem or a volume problem.
Begin with the Rule Numbers, in the Rule Execution section:
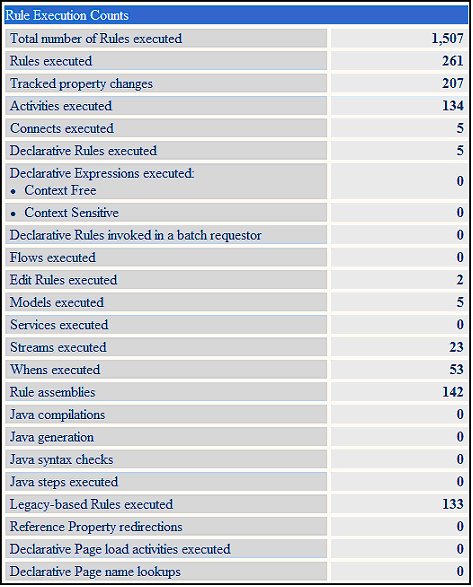
The Rule Execution counters are measures of volume (how many Activities ran, how many Flows, etc.). Individually, these counters may not be able to give a developer a good indication of a problem (unless the numbers are huge – if you are running 800 Activities just to open a Work Object, then that is probably too complex a process). However, looking at these counters as a group can give a developer a picture of the level of complexity of the Work Object process.
If there is a large count in one of the Rule execution counters (Activities, Flows, Models, Streams, etc. Executed), then focus there; use Tracer (not DB Trace, which is for database) to find out what part of your business process is consuming a lot of CPU.
If the numbers for these counts is low (even if the CPU is high), then there is not an issue with the Rule Execution processing being done, and investigation continues.
For details on Database Access counters or Requestor Summary readings, see those sections below.
If none of the counters point to something definitive, the problem may be in something that is not being directly measured, which would be in the application processing itself.
Medium Total CPU Reading
If the CPU is not a definitively high reading, but it is a medium value (a bit higher than recommended), that is not necessarily a problem.
To determine whether there is a problem, compare the Total CPU Time number with the Total Elapsed Time. What percentage of the Total Elapsed is Total CPU? If the ratio is high – i.e., the CPU time is a large percentage of Total Elapsed – then investigate the CPU number, even if the Total CPU number is not that large. (A high ratio may indicate too much CPU time being spent processing data.) If the ratio is low, then CPU is probably not the issue.
Move on to the next investigative area, but keep an eye on the CPU numbers; a problem of scale (adding many users) may develop in the future. (NOTE: If CPU is high, there is already a scaling problem – more users cannot be added without maxing out the system capacity.)
Low Total CPU Reading
Low Total CPU readings are generally healthy). The developer could check the ratio of the Total CPU Time to Total Elapsed Time, to see what percentage of Total Elapsed the CPU consumes. If this ratio is high, and the overall Total CPU number is low, then that signifies that the majority of time that is being spent on a Work object is for processing, and that the processing is efficient (low CPU). This shows a well-designed application.
Total Elapsed Time
If the CPU investigation is inconclusive, the next major step in the analysis is to look at Total elapsed time for the reading(s).
As with the Total CPU reading, based on whether the Total Elapsed reading is High, Medium, or Low, different analysis paths may be chosen.
Total Elapsed time
Description
High
An Elapsed reading could be considered high if it was over a second per screen.
Medium
Between .5 and 1 second per screen.
Low
Under .5 seconds per screen.
For this reading, the focus will be on Elapsed time counters which are disproportionate to the CPU time, or that don’t have CPU associated with them (such as Elapsed Time executing Connect Rules) when the number is large.
High Total Elapsed Reading
Connections to other systems and database times are typical problems in Elapsed time readings – the time spent getting data from other systems. There may be too many calls to another system, or the other system may be slow in responding.
Note that if Java steps are used within Activities, it is not possible for PAL to measure those directly. The focus for PAL is on more external processes such as Rules Assembly, or accessing data from outside the engine (such as the database or an external data source).
To determine where the problem of high elapsed time originates, look at the Elapsed Time Detail section on the DELTA Detail screen:

NOTE: Depending upon the processing done, not all of these readings may contain data.
Add up all the Elapsed counters, and subtract that number from the Total Elapsed Time. The difference between the sum and the Total Elapsed is again related to the processing of the application. The direct actions of querying the database and getting the Rules ready for execution is tracked by the PAL readings; the actual application processing is not, as it is different for every customer.
If any of the Elapsed counters are a high percentage of the total, that needs to be investigated.
Example:
From the above example, a DELTA reading was taken after a work object was processed. This delta reading shows that Total Elapsed was .67 seconds:
PAL Reading
Value (seconds)
Percent of Total
Total Elapsed Time
28.56
100%
accessing non-rule-resolved instances from database
.78
2.73%
retrieving rule-resolved Rules from the database
18.08
63.30%
executing Declarative Rules
.02
.07%
retrieving Declarative Rules
.65
2.27%
retrieving non-Rule database lists
.54
1.89%
retrieving Rule database lists
.2
.7%
processing Storage Streams for Rule database lists
.1
.35%
performing Rule assembly
5.69
19.92%
In the above example, retrieving rule-resolved Rules from the database takes about two-thirds of the Total Elapsed Time. Again, these readings measure the elapsed time spent retrieving and compiling Rules for execution; thus, it may be that the Rules Assembly process was being executed here, and another reading of the same process may result in lower readings.
Special Case: If the Total Elapsed Time for the Reading(s) is a high number, but the individual CPU times are low, then there might be another process running in the JVM that is consuming large amounts of resource and impacting response time. This might be:
- an agent (set to wake up too frequently, like every second)
- garbage collection (again, happening too frequently)
- the JVM itself
- listeners (for email and other processing – check file listeners and MQ)
This issue may be pinpointed by looking at the Process CPU, which is displayed at the top of the detail screen:

The Process CPU displays the CPU time consumed by all requestors in the system (not just one requestor, which is what the detail information shows) since the JVM was started. To check whether another process is running on the JVM, take one PAL reading, wait maybe 10 seconds, and then take another, without doing any other actions (like opening work objects). If the Process CPU number at the top of the next Detail screen changes noticeably, then that shows that the CPUs are busy working on other processing.
Database Access Counts
The Database Access counters show the counts of Rules (or non-rules, like Work- or Data-) that were read from the database. (This is not the number that was actually executed - that would be Rule Execution.) Database Access shows the number of rules that needed to be read in order to determine the Rules to execute. For Rule Resolution (for example), the system could load many rules, which are then all evaluated to choose the one best rule for the situation. Looking at the Rules accessed shows how much database access is done before the chosen Rule gets executed; a high number of retrieved Rules for each Rule executed could indicate that the system is doing a great deal of database access in order to find the Rules to execute, and might need to be optimized.
These readings can also show whether there is a problem with database response speed. The timers can show the time that the system spends processing, but there is no way to directly track the amount of time the third-party relational database spends processing; that information may only be found indirectly.
CPU readings will not necessarily indicate whether there is a problem with database response times. Processing one massively complex SQL query may take several full seconds and return only one row. This will not be counted as a CPU time issue, as CPU measures the time the Process Commander system is processing – not the database processing time. In the case above, the long query would not be seen in the CPU reading, but in the Elapsed time reading, which shows the full time (CPU and other, such as database processing) that was required to return results from the database.
Database counters can help specify whether the problems is with a small number of the aforementioned massively complex queries, or whether the issue is an excessively high number of queries (even though they may be simple queries).
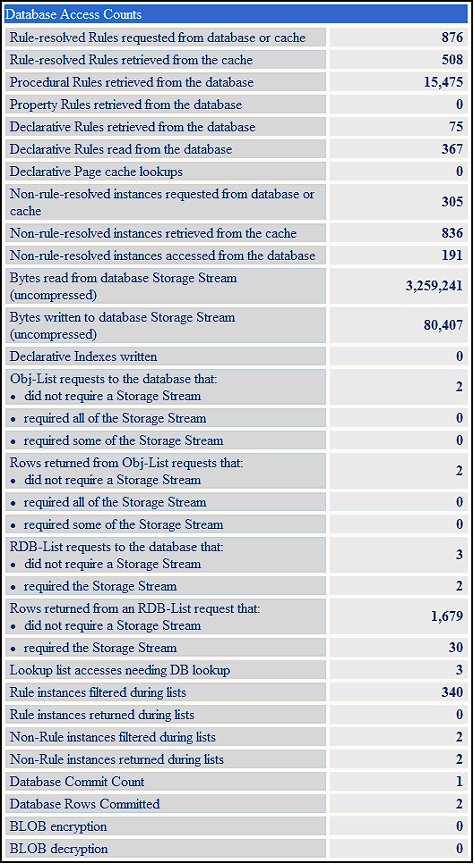
Database queries come in two types:
- queries as a result of the Rules that are running
- queries that are the result of the actions of running Rules
Queries that are a result of the Rules that are running – The act of needing a Rule (to run) may cause database queries to occur, when processing such as Rule Resolution takes place (which is trying to determine the best Rule to run in a specific situation).
Queries that are the result of actions of running Rules - This type of query is involved in the actual actions the Rules are performing – when a report is run, which uses an Obj-Open Method, or an RDB-Save; these rules actually perform work on the database.
Storage Stream
All of the Process Commander data is stored in the Storage Stream column, which is also known as the BLOB – the Binary Large OBject column. This column is currently part of all PegaRULES database tables. It is used to store data that is structured in forms that do not readily “fit” into the pre-defined database columns, like properties that contain multi-dimensional data such as pages, groups or lists. Some Process Commander data may also be stored in “exposed” columns in the database table; these are separate columns in the table which hold data from scalar properties.
When the Storage Stream is present in a database table, all the data in each instance written to that table is stored in the Storage Stream column, including some of the data which might also be in exposed columns in the table. The reason for this storage arrangement is twofold:
- it is not possible to run reports on the data in the Storage Stream, so any properties upon which queries will be run must be in exposed columns
- when extracting data from the database, since some of the information is stored in the Storage Stream and some in exposed columns, it is faster for the system to read it all out of the Storage Stream
Storage Stream data handling is slow, and it takes up a lot of space. Due to the volume of data stored in this column, Process Commander compresses the data when storing it in the column, using one of several compression algorithms (“V4”, ”V5,” or “V6”). When data is requested from the Storage Stream, it must be read from the column and decompressed onto a temporary clipboard page; then, since the Storage Stream includes all the properties in a particular table entry, the data must be filtered, so that only the requested properties are returned; the temporary clipboard page is then thrown away.
If this entire process is run to only extract one property from the Storage Stream, that is a highly inefficient and costly setup. It may be that certain properties which are frequently reported on should be exposed as columns in the database table, if they are continually read from the Storage Stream. This then allows them to be read directly, rather than going through the above process.
Database vs. Cache
Some of the Database Access counts also display the number of times that data is found in a system cache. There are a number of different caches in Process Commander, which help optimize processing. If a Rule is required for some processing, the first thing that is done is to check the cache to see if that Rule has been accessed before in the current system setup. If it has, the system doesn’t have to go to the database to retrieve this Rule; accessing the Rule from the cache is much more efficient than having to retrieve it from the database - especially if this Rule has data in the Storage Stream that must be retrieved.
Once it has been determined that requested information is not in the cache, and the system must go out to the database for that information, it will then be stored in the cache for the next request. Thus, the longer users work on the system, the more efficient their processing should be. If this expected efficiency increase does not occur, the developer should investigate the situation. (Perhaps all the users have different RuleSets, which prevents reuse in the cache, or perhaps there is so much information being cached that the cache is running out of room and clearing out the older entries; or perhaps there is some other problem.)
Likewise, once the system has been running for some time, all the Rule Resolution should be done and cached. If the Rule-resolved Rules continue to be accessed from the database, with all the processing that requires, there is something wrong with the system setup.
Lookup Lists
Forms may include one or more lookup lists (the fields which have the small triangle in the lower right corner, which indicates that using the down-arrow will create a list of appropriate entries for that field). Lookup lists involve a lot of processing and database lookup, so there are a number of PAL counters available to give detail on their system expense.
There are two main types of database SQL query which are used for Lookup Lists:
- Obj-List - allows the developer to specify the conditions of their query in higher-level language, using the Process Commander objects (example: “Return a list of all work items where the Customer is Acme Corp”). Process Commander then translates this request into SQL and queries the database.
- RDB-List - allows the developer to specify the conditions of their query directly in SQL. These queries are made through Rule-Connect-SQL instances.
As stated in the Storage Stream section above, most data is stored in the Storage Stream (BLOB) column, with only a few exposed columns. When information is queried from the database and must be returned from the Storage Stream, uncompressing and filtering this information (to return only the data that was requested) has a high resource cost. It is vital to the performance of the system that queries be designed carefully, to prevent unnecessary extraction of information from the Storage Stream. (For example, if a particular property is requested frequently from the Storage Stream, it may markedly increase performance to expose that column in the database, so the Storage Stream does not need to be decompressed and filtered to get that one property.)
Therefore, some of the PAL counters measure whether the information requested from the database came from the Storage Stream or not, and whether all of the BLOB data was needed by the request, or just some of it. If all the information was needed from the Storage Stream, that is overall a less wasteful query than having to extract the entire Storage stream just to get a value for one property.)
The below PAL counters measure how the data was requested from the database – by using Obj-List or RDB-List, and whether those requests used the Storage Stream.
Obj-Listrequests to the database that:- did not require a Storage Stream
- required all of the Storage Stream
- required some of the Storage Stream
Rows returned from Obj-Listrequests that:- did not require a Storage Stream
- required all of the Storage Stream
- required some of the Storage Stream
RDB-Listrequests to the database that:- did not require a Storage Stream
- required the Storage Stream
Rows returned from RDB-List requests that:
- did not require a Storage Stream
- required the Storage Stream
For the list returns which are filtered (i.e., “required some of the Storage Stream”), the above counters do not state whether the request was for Rules or non-Rules. Additional counters give more detailed information:
- CPU time processing Storage Streams for Rule database lists
- Elapsed time processing Storage Streams for Rule database lists
- Rule instances filtered during lists
- CPU time processing Storage Streams for non-Rule database lists
- Elapsed time processing Storage Streams for non-Rule database lists
- Non-Rule instances filtered during lists
The following PAL counters don’t depend on the method used to request the list information, but measure the time spent generating lists of objects. (These lists may or may not include the Storage Stream data.)
- CPU time retrieving Rule database lists
- Elapsed time retrieving Rule database lists
- Rule instances returned during lists
- CPU time retrieving non-Rule database lists
- Elapsed time retrieving non-Rule database lists
- Non-Rule instances returned during lists
Measuring Commits
During processing (such as running an activity), there are two types of commits which can be done to save data to the database:
- immediate
- deferred
The immediate commit is done from an Obj-Save step in an activity which has the WriteNow parameter checked. If this parameter is checked, then as soon as the Obj-Save step is reached, the data will be saved to the database.

If the WriteNow parameter is not checked, then the commit is deferred. Later in the activity, an explicit Commit step must be included:

If this Commit step is not included, then whatever data was processed on the clipboard by this activity will not be saved to the database.
Due to the difference in these two processes, different types of PAL counters were created to track them:
- Database Commit
- Accessing non-rule-resolved instances
Database Commit counters
These counters track the deferred commits (the ones where the commit must be explicitly stated, or explicit commits), and include the following PAL readings:
- Database Commit Count
- Database Rows Committed
- Elapsed time performing explicit database commit operations
Accessing non-rule-resolved instance counters
These counters track the immediate commits, and include the following PAL readings:
- Elapsed Time accessing non-rule-resolved instances from the database
- Non-rule-resolved instances accessed from the database
These counters show information about saving data to the database. A balance must be found between number of commits and the amount of time it takes to commit data. If the number of commits is very high, is the application saving more times than it needs to, or is there just a very high volume of work objects? Perhaps fewer commits might mean less database processing. If the elapsed time to save is high, does that mean that too much data is being committed at once? If so, then perhaps more commit statements might be needed, in order to take less time to commit all the data.
Requestor Summary
The Requestor summary shows general information about this requestor (the user’s interaction with the system). Several key readings in this section include:
- Clipboard pagesare tracked in the Number of Named Pages Created reading. The number of named clipboard pages, if high, indicates complexity in the clipboard structure. This might be where a lot of the processing is happening. If a great deal of information is being loaded onto the clipboard from database queries, and hundreds of Named Pages are being created, that will impact performance.
- Number of Input Bytes received by the server and Number of Output Bytes sent from the server show how much work is being done to render the screen for the user (the HTML information necessary for the browser). High values might indicate an unnecessarily complex screen.
Database Requests Exceeding Threshold
The limit on the amount of time one database query should require is set by default to a half-second (500 milliseconds). In the Requestor Summary section, the counter Number of database requests that exceeded the time threshold shows how many database requests in one measurement went over this threshold. If database requests exceed the threshold, this might indicate overly complex queries. Investigate this possibility by using DB Trace tool.
You can override this threshold value by updateing the prconfig.xml file, change the value for the
operationsTimeThresholdentry:<env name="alerts/database/operationTimeThreshold" value="500"/>
In addition to displaying the requests exceeding the threshold in the PAL Detail screen, this information is written to the PegaRULES-ALERT-yyyy-mmm-dd.log file (example: PegaRULES-ALERT-2005-Nov-17.log). For each interaction where the threshold is exceeded, an entry is made in the log file. This entry includes:
- the warning “WARN – Database update took more than threshold of 500 ms” and the measurement of the amount of time the request took
- the SQL query that caused the alert
- the substituted data for the query
Example:
02:59:02,328 [sage Tracking Daemon] (base.DatabasePreparedStatement) WARN - Database update took more than threshold of 500 ms: 520.1726808741121 ms
02:59:02,328 [sage Tracking Daemon] (base.DatabasePreparedStatement) WARN - SQL: insert into pr4_log_usage (pxActivityCount , pxCommitElapsed , pxConnectCount , pxConnectElapsed , pxDBInputBytes , pxDBOutputBytes , pxDeclarativeRulesInvokedCount , pxFlowCount , pxInputBytes , pxInsName , pxInteractions , pxJavaAssembleCount , pxJavaCompileCount , pxObjClass , pxOtherBrowseElapsed , pxOtherBrowseReturned , pxOtherIOCount , pxOtherIOElapsed , pxOutputBytes , pxProcessCPU , pxRequestorID , pxRequestorStart , pxRequestorType , pxRuleBrowseElapsed , pxRuleBrowseReturned , pxRuleCount , pxRuleIOElapsed , pxServiceCount , pxSnapshotTime , pxSnapshotType , pxSystemName , pxSystemNode , pxTotalReqCPU , pxTotalReqTime , pyUserIdentifier , pzInsKey) values (? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ? , ?)
02:59:02,328 [sage Tracking Daemon] (base.DatabasePreparedStatement) WARN - inserts: <0> <0.0> <0> <0.0> <0> <0> <0> <0> <0> <BD65DE7294464B6265522D2AA7A414F1E!20051120T075744.501 GMT> <0> <0> <0> <Log-Usage> <0.0> <0> <0> <0.0> <0> <112.6875> <BD65DE7294464B6265522D2AA7A414F1E> <2005-11-20 02:57:44.501> <BATCH> <0.0> <0> <0> <0.0> <0> <2005-11-20 02:57:44.501> <INITIALIZE> <wfe> <sdevrulesb> <0.0> <0.0> <<null>> <LOG-USAGE BD65DE7294464B6265522D2AA7A414F1E!20051120T075744.501 GMT>
Parsing Statistics (seconds)
Process Commander has the capability to receive and parse different types of files from external systems. For example, a bank might have a legacy system which contains its daily transactions from other banks, which need to be merged into its Process Commander system.
There are three types of parse rules:
Rule Type
Description
Rule-Parse-Delimited
Used to parse comma-delimited files. If the file is delimited, this rule can be set to stop at the specified delimiter and map that value to a specified property on the clipboard.
Rule-Parse-Structured
Used to parse structured files. This rule can be set to use the file structure to extract certain information (example: “Every 25 characters, extract the next 5 characters”) and map that information to a specified property on the clipboard.
Rule-Parse-XML
Used to parse XML files. If an XML file is parsed, this rule can be used to parse the XML code, find a particular element, and map that element to a specified property on the clipboard.
Beginning in Version 5.1, this section of the PAL Detail display tracks the number of parse rules run during an interaction, and the amount of time required for the parsing process:

As with the other CPU and Elapsed Time measurements, an excessive amount of time spent parsing rules (over ½ second) may indicate an issue with the data which needs to be investigated.
Services Statistics (seconds)
Process Commander may also be called by other systems for Business Rules Engine processing. The Service Rules may be used to set up these processes. Beginning in Version 5.1, the Services Statistics track the time spent running these Service Rules.
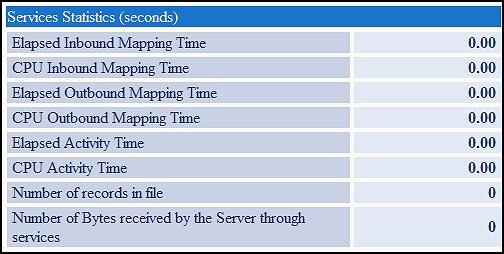
The Service Rule functionality is broken down into three steps:
- Inbound mapping
- Activity execution
- Outbound mapping
This allows the developer to pinpoint where performance problems may be occurring. For example, the external system may send a very large file to the Process Commander application, but only part of that file may be needed for the processing. The time to process this file may show:
Inbound Mapping Time: 5 seconds
Activity Time: .2 seconds
Outbound Mapping Time: .2 seconds
None of these processes should take more than ½ second. With this data, the developer can look more closely at the inbound mapping activities to see why that takes such a large amount of time.
Connects Statistics (seconds)
Process Commander may also connect to external systems for data to use in processing work objects. The Connect Rules may be used to set up these processes. Beginning in Version 5.3, the Connects Statistics track the time spent running these Connect Rules.

The Connect Rule functionality is broken down into three steps:
- Outbound Mapping
- External system processing
- Inbound mapping
This allows the developer to pinpoint where performance problems may be occurring. For example, the external system may take a very long time to process the request (which would not be a Process Commander problem). The time to process the Connect might show:
Outbound Mapping Time: .2 seconds
External system Time: 10 seconds
Inbound Mapping Time: .5 seconds
None of these processes should take more than ½ second. With this data, the developer can look more closely at the external system processing to see why that takes such a large amount of time.
Additional Resources
The information in this article is taken from the
 Using Performance Tools System Tools paper. This file includes a glossary containing definitions of over 130 PAL counters. For easier searching and viewing, this System Tools paper is published as a series of four articles:
Using Performance Tools System Tools paper. This file includes a glossary containing definitions of over 130 PAL counters. For easier searching and viewing, this System Tools paper is published as a series of four articles:- PAL: Overview of Performance Tools and Information Collection – An overview of the Performance Analysis tool and its methodology, written for all users; also a section on Collecting Performance Information, which is written for all users, and describes the method of collecting this data to give to your application developer.
- PAL: Understanding Performance Information - This section is designed for application developers, and describes the different performance tools in detail. It looks at the specifics of what the PAL readings measure, as well as how to use them to better understand and improve the performance of your application.
- Performance (PAL) Detail Screen – This article
- DB Trace and Profiler – DB Trace helps developers understand the details of the database interactions. (It is easy for database access to become a performance bottleneck – this tool raises the visibility of the database processing.) The Profiler allows users to trace steps within an activity.
Previous topic Interpreting Performance Tool (PAL) outputs Next topic Overview of the Performance Tools (PAL)