Interpreting Performance Tool (PAL) outputs
Summary
After the PAL data has been collected for an application, it is necessary to analyze the information. Process Commander gives the application developer a number of performance tools for this analysis.
- the PAL Detail display (see Interpreting the Performance Tool (PAL) Detail display)
- DB Trace (see Using the DB Trace and Profiler tools to understand performance)
- Profiler (described in detail in the article Using the DB Trace and Profiler tools to understand performance)
This section begins with an overview of the factors that affect an application’s performance; the linked articles describe the tools in detail.
IMPORTANT: In Version 5.3, PAL timer values are “mutually exclusive.” Prior to V5.3, when (for example) a declarative network was built to run a Declare Expression, the Elapsed Time Executing Declarative Rules might be higher than the Total Request Time, due to the fact that the former included other processing that was also occurring, such as Rule I/O, Other I/O, etc.; the Declarative timer was counting time that was also counted in another timer.
Beginning in Version 5.3, if one timer is going and another is triggered, the first timer stops (temporarily so that the time is not double-counted. In the above example, if the Rule I/O timer starts, the Executing Declarative timer stops until the Rule I/O processing is finished, and then continue tracking the Declarative processing.
NOTE: The only exception to the “mutually exclusive” setup is Total Request Time, which accumulated no matter what other timers are running.
Quick Links
Suggested Approach
The Theory of PAL
Factors Affecting Performance
There are a number of factors which may affect an application’s performance. The availability of resources is central to performance issues – either consumption of resources (resources which may run out, such as memory space), or contention of resources (too many applications trying to do the same thing, such as access a database).
There are four resources that can be consumed by an application:
- memory
- CPU
- disk I/O
- network
Resources can contend due to:
- single-threaded resources
- saturation of resources
In addition, other factors may impact performance:
- Garbage collection – Refer to Support Play: Tuning your JVM for your system for details on the most efficient garbage collection setup. See Index: Support Plays.
- Agents
Information required before using PAL
Gather this information before using PAL, so you can interpret the PAL readings.
1. The number of processors on the server, and the speed of each processor.
Many PAL readings measure CPU time, usually reported in seconds. CPU time should be used to help normalize readings across server machines (to make sure that comparisons are accurate). A processor that runs at (for example) 1GHz would process half the work in a second that a processor running at 2GHz would accomplish; therefore, “one second” of CPU time on the 1GHz processor would not be equal to one second on the 2GHz machine. This inequality must be taken into account when measuring performance.
In addition, consider the number of CPUs in the machine. If servers have different numbers of CPUs, then comparing the capacity of these servers requires some calculation
Example:
A development/test server may have a 2GHz processor, but only one CPU.
The production system may have a 1GHz processor, but four CPUs.
The development machine runs a process that requires one second of CPU time. With one CPU, the maximum number of users who can do this operation would be 60 in a minute (60 seconds/minute).
The production machine is slower, so it takes two seconds to run the same process (only a 1GHz processor). However, there are 4 CPUs, so 120 users may run this process in a minute. The production system has twice the capacity, but the response time is degraded.
2. Application Type and Usage Profile
It is necessary to understand what the application is doing, and how it is used – how many work objects are handled per hour, how many users are simultaneously using the system - in order to add context to the PAL readings. (For example, a call center where each person handles 20 work objects per hour will have different performance requirements than some kind of dispute center, where people might handle one item per hour.)
The application developer must know what factors they are trying to tune in the system, which could include:
- business transaction arrival rate – the rate at which the users expect the business transactions (work objects) to arrive. It is important to understand the business transaction arrival rate before defining a set of load test scenarios; in particular, the types of business transactions being executed, and the proportional mix of those transactions (for example, the application expects to run 200 call entries a day, or 25 per hour/one every 2 ½ minutes, as well as 10 manager reports in the morning)
- response time – the speed at which the system completes the processing requested by the user and is available for the user to begin their next work (for example, how long the user has to wait for a new Work Object to open)
- resource utilization – the efficiency with which the application completes the processes, and the number of simultaneous processes that may be available.
3. Network Architecture
When assessing performance of applications, an understanding of the network architecture between the application server and the client is necessary. If the application server is on the same local area network as the client, the application workflows will be tuned differently, and may have different design criteria, than if the client and application server are separated on different LANs or WANs.
- A Local Area Network works most efficiently with traffic composed of lots of little packets
- A Wide Area Network works most efficiently with traffic composed of few but large packets (such as FTP)
4. Performance expectation
Along with what kind of work the application is doing, it is necessary to understand the expectation of the users regarding performance. It may be that a system which is running at its absolutely most efficient speed might refresh a work object in 10 seconds (due to the complexity of the application screens); if the users expect the system to refresh in one second, there will be a perceived lack of performance, even if the system is tuned to peak efficiency. On the other hand, if an application takes two full minutes (120 seconds) to process a work object, but this processing used to take three weeks, that might be considered excellent performance.
NOTE: If the performance time is unknown, begin with the assumption that each screen should take less than one second.
5. Detailed Application Knowledge
PAL readings are taken at many levels in the application, with lots of good data. However, it is important to know what in the application the numbers point to. For example, the PAL data may show 200 database reads for a work object. The application developer must be able to understand the work object structure of the application, in order to find the work object and actually solve the problem and reduce the database I/O.
PAL Tools
PAL readings are taken for each requestor, and measured on the server (not the client side of the application). These readings are grouped into several types, signified by keywords in their labels:
- number/count
- CPU
- elapsed (a.k.a. ‘wall time’)
Number is a count of the number of times a specific action occurs. Example: Rules executed measures the number of times a Rules-Assembled Rule is executed.
CPU is the amount of CPU processing time, in seconds, that this action takes for this thread. Example: CPU time compiling Rules measures the amount of CPU time the system takes to compile the generated Java code for a Rule.
Important: CPU readings are not tracked for systems running on UNIX platforms. Since PAL readings are taken constantly in the system in order to measure the application performance, they must never impact the performance themselves – PAL should not take up significant resources trying to figure out more efficient resource use. On UNIX systems, the gathering of thread-level CPU data has a significant impact on the performance of the system; therefore, it was decided not to gather the thread-level CPU information in UNIX, as the reading itself impacted the performance being measured.
Elapsed is the system time, in seconds, that a process takes; this time includes the CPU processing time. Thus, this time is generally equal to or longer than the CPU time. Example: Elapsed time compiling Rules measures the amount of elapsed (system) time the system takes to compile the generated Java code for a Rule.
For each PAL reading, a specific point in the code has been instrumented. For example, for the reading Activities Executed,when anything in the engine requests an Activity to run, the Activities ExecutedPAL counter is acquired and incremented. Likewise, for every compile of generated Java code that is done, the system acquires the Java CompilationsPAL reading and increments it; it also starts a CPU and an Elapsed timer for the compile; calls the engine code to compile, and then stops both timers.
PAL readings are gathered at two levels:
- Requestor
- System (Node)
A Requestor is a list of Threads, and is associated with one user ID. When the Reset Data link is clicked, the Requestor-level data for the user’s requestor will be reset to zero, whereas the system-level data is unaffected.
Most of the System/Node counters are displayed on the System Console; only a few (such as System Cache Statusor Database time threshold)are displayed in the PAL Detail Screen.
Performance Tool
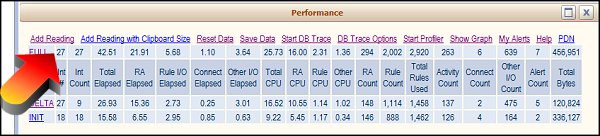
To view PAL readings in V5.1 and later, select the Run > Performance menu item in the Developer portal.. The Performance display appears:

PAL displays the system readings as they exist now, summed up to the present. This information is shown as three types of readings:- INIT – the first full reading from this PAL display. This reading will never change, unless the Performance numbers are Reset.
- FULL – the last full reading of the readings. If there are any Delta readings, the Full reading will display the Init reading plus the Delta reading. The Full reading shows the Performance numbers summed up to the present.
- DELTA – the difference between the current full reading and the last full reading.
Interactions
An interaction is counted whenever the browser or the requestor makes a request of the server. Thus, each request/response of the server is an interaction. A business process will probably have more than one interaction; a single screen could require many trips to the server for all the required information. Lookup lists require many interactions. (For example, the act of starting up Process Commander in the browser for a user involves about 15 interactions.)
NOTE: The Interaction count does not include static content, such as JPG files (like the sign-on screen being sent to the client).
Some interactions are required by Process Commander and can’t be controlled (such as sign-on), but many are controllable. The number of interactions for a particular action (Open a Work Item) may indicate how efficiently the application is designed (if it takes 250 interactions to open a work item, this is an inefficient or overly complex form).
Interactions are the lowest common denominator to measure and analyze the results of a PAL trace. Developers may find it useful to divide a PAL reading by the number of interactions comprising it, to get the counts per interaction, for comparison purposes with other PAL traces.
NOTE: Running PAL itself creates one interaction. Thus, if Add Reading is clicked without doing any other work in the system, the Interaction # and Interaction Count will increment by one.
The interaction numbers may also be used to track and compare the PAL information. For example, if a user takes different PAL readings when gathering information for analysis, and also runs a DBTrace, then the interaction numbers in the Trace can be matched to the PAL readings during the analysis.
 The interaction numbers identify what data is in the PAL readings for INIT, FULL, and DELTA. For example, in the above image, after signing in to Process Commander but before doing any work, clicking Performance to display the PAL data will show just an INIT and a FULL reading. The number of interactions is 19, which is 18 for sign-on and one for PAL, and the readings for INIT equal the FULL readings because no deltas have been added.
The interaction numbers identify what data is in the PAL readings for INIT, FULL, and DELTA. For example, in the above image, after signing in to Process Commander but before doing any work, clicking Performance to display the PAL data will show just an INIT and a FULL reading. The number of interactions is 19, which is 18 for sign-on and one for PAL, and the readings for INIT equal the FULL readings because no deltas have been added.
After some work has been processed, a DELTA reading can be added (using Add Reading).
- The number of Interactions (Int #) for the INIT reading will stay the same, as the initial reading is there to serve as the baseline.
- The number of interactions for FULL shows 30, as that is how many interactions there have been for this requestor.
- Interactions for the DELTA reading show 30, as it measures up to the full number of interactions for this requestor; however, the Interaction Count is 11, showing the difference between the INIT reading (at 19) and the FULL reading (30).
Clicking the FULL, INIT, or DELTA labels will show detailed PAL data for these readings.
- Clicking FULL will display PAL counter readings for all interactions (1 through 30).
- Clicking INIT will display the PAL counter readings for the original baseline (interactions 1 through 19).
- Clicking DELTA will display PAL counter readings of the difference between the original baseline (INIT) and the final FULL reading (interactions 20 through 30).
For any PAL reading, beginning with the INIT data and adding all of the DELTA data should give the FULL reading.
Note that as the number of interactions increases, the performance may decrease, as the system is having to do more work passing information to and from the server. For each screen in a Work object, in order to render the screen, one or more interactions with the server will be required; screens may be considered a collection of interactions.
If there are a large number of interactions required to render one screen (15 – 20 or more), this very high number should be investigated for performance issues. Each trip to the server may not require a lot of CPU processing (so total CPU might not be high), but the trips themselves take time.
Detail Display
Clicking the name of the INIT, DELTA, or FULL type of readings to display a detail screen of the data for that reading.
Information on using these readings is found in the Interpreting the Performance Tool (PAL) Detail display.
PAL Features
There are a number of action links at the top of the PAL display.
Add Reading
Clicking Add Reading will take another reading of the PAL data, and add a Delta reading to the Performance Readings display.
Top of page
Add Reading with Clipboard Size
This function will not create any difference in the display of the summary view of the Performance readings; it will only show a change in the Delta detail screen.
Clicking Add Reading with Clipboard Size will add a Delta reading. When the Requestor Summary section of that Delta detail is viewed, the Requestor Clipboard Size (bytes) reading will show the estimated size of the Clipboard in memory (in bytes). This includes the clipboard pages that belong to all the threads of that particular requestor.
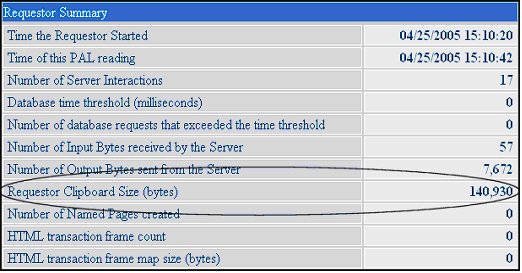
If Add Reading with Clipboard Size is not clicked, this reading displays zero.
NOTE: The Requestor Clipboard Size reading is an expensive operation, which is why it must be requested (rather than running automatically, like the other readings).
Reset Data
This function resets all the displayed data for the requestors to zero.

The above display shows that almost all the counters have reset to zero. The ones that did not are the ones involved in creating the PAL display itself. Thus, the time shown for Total Elapsed and for Total CPU is the time required to create the PAL reading. The Total Rules Used and the one Activity also relate to the PAL reading.
Save Data
Click Save Data to save the data that is currently in the PAL display to a comma-delimited CSV file. You are prompted to name the file and identify to the directory on your Windows workstation where this file will be saved..
The file may then be reviewed by using a program that reads CSV format (such as Excel).
Start DB Trace
See Using the DB Trace and Profiler tools to understand performance.
DB Trace Options
See Using the DB Trace and Profiler tools to understand performance.
Start Profiler
See Using the DB Trace and Profiler tools to understand performance.
Show Graph
Click to present a chart that displays of PAL readings in graph format, to show the percentages relative to the Total Elapsed Time for a reading.
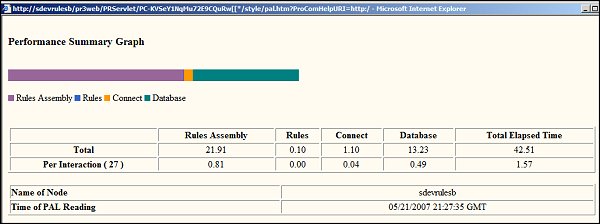
The combinations are as follows:
Column name (on graph)
PAL counters (added together)
Rules Assembly
Elapsed time performing Rule Assembly +
Elapsed time compiling Rules +
Elapsed time checking Java syntax
Rules
Elapsed time executing Declarative Rules +
Elapsed time processing Storage Streams for non-Rule database lists +
Elapsed time processing Storage Streams for Rule database lists
Connect
Elapsed time executing Connect rules
Database
Elapsed time accessing non-rule-resolved instances from database +
Elapsed time retrieving rule-resolved Rules from the database +
Elapsed time retrieving Declarative Rules +
Elapsed time retrieving non-Rule database lists +
Elapsed time retrieving Rule database lists +
Elapsed time performing explicit database commit operations
My Alerts
This link shows alerts which were generated by the current requestor. (It is also possible to look at My Alerts from the Tools menu.) This link displays the relevant entries from the current Alert log on the server node.
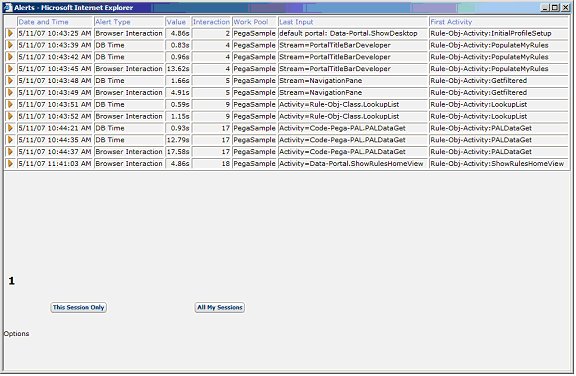
The data shown includes:
Field
Description
Date and Time
The date and time of the alert. (This information is converted from GMT, which is the data stored in the database, to the time zone of the server.)
Alert Type
A text description of the alert type. (For example, the text Browser Interaction corresponds to alert type PEGA0001.)
Value
The actual value of the Key Performance Indicator being tracked by the alert.
Interaction
The number of the interaction upon which the alert was issued.
Work Pool
The work pool that the requestor is using (or “none” if none is specified).
Last Input
A portion of the URL received by the server in the most recent interaction before the alert. (This is usually the text “Stream =” or “Activity =” and the name of the activity or stream rule which was run by that URL.)
First Activity
The first activity or stream which was run by this requestor in the current interaction. (NOTE: This activity or stream may not have directly caused the alert.)
For more details on the Pega Alerts, see the Autonomic Event Services Guide.
The other links/buttons on this screen include:
Link or Button Title
Description
“1”
(a number)
If only one page of alerts exists for this requestor, then only one number will appear. If there are several pages of links, multiple numbers (corresponding to the pages: 1, 2, 3, etc.) will appear. Click the appropriate link to view the desired page of alerts.
This Session Only
Click this button to limit the display to the alerts produced by the current requestor session.
All My Sessions
Click this button to display alerts from the current session and all other sessions with this requestor.
Options
Click this link to view or set log-filtering criteria. (See Help for further details on the Options.)
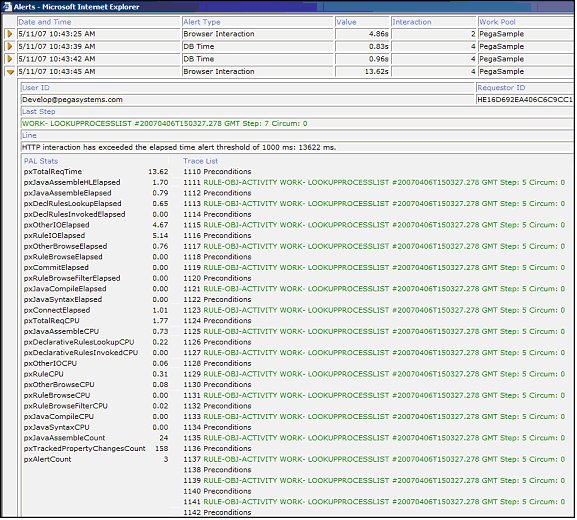
For each alert, you can click the orange arrow to the left of the alert, to display full details about that particular alert, including the alert message and a traceback of the rules executed.
Example: “HTTP interaction has exceeded the elapsed time alert threshold of 1000 ms: 13622 ms.”
Additional Resources
The information in this article is taken from the
 Using Performance Tools System Tools paper. That document includes a glossary containing definitions of over 130 PAL counters.For easier searching and viewing, that System Tools paper has also been published as a series of four articles:
Using Performance Tools System Tools paper. That document includes a glossary containing definitions of over 130 PAL counters.For easier searching and viewing, that System Tools paper has also been published as a series of four articles:- Overview of the Performance Tools (PAL) – An overview of the Performance Analysis tool and its methodology, written for all users; also a section on Collecting Performance Information, which is written for all users, and describes the method of collecting this data to give to your application developer.
- PAL: Understanding Performance Information - This article.
- Interpreting the Performance Tool (PAL) Detail display – details on the PAL counters being tracked in the system, and how to interpret the groupings.
- Using the DB Trace and Profiler tools to understand performance – DB Trace helps developers understand the details of the database interactions. (It is easy for database access to become a performance bottleneck – this tool raises the visibility of the database processing.) The Profiler allows users to trace steps within an activity.
Previous topic How to run the DBTrace tool in a production system (V5) Next topic Interpreting the Performance Tool (PAL) Detail display