Monitoring the progress of your case archival process
The pr_metadata table holds all of the pyArchiveStatus and other information about all records that are processed by the three archival jobs.
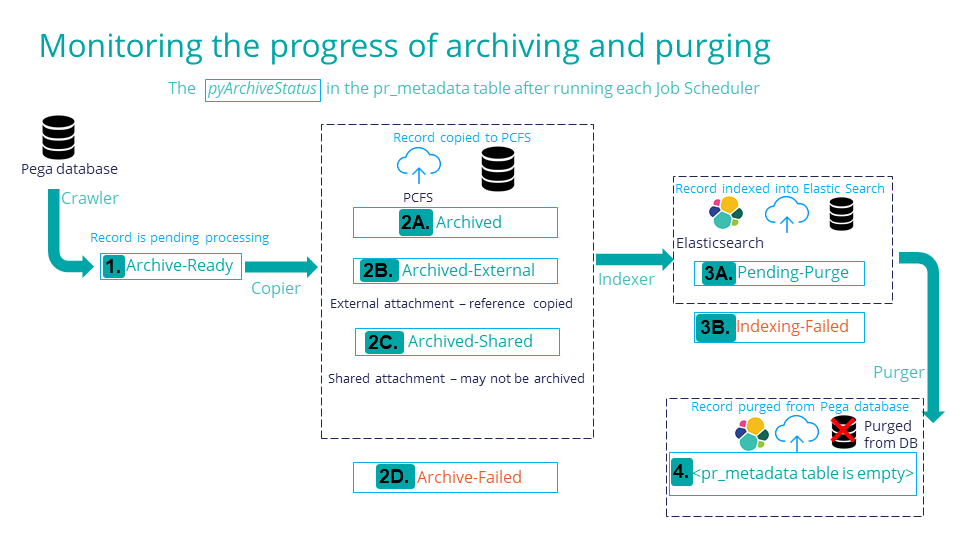
| pyArchiveStatus | Callout | Description |
| Archive-Ready | 1. | (Status occurs after the Crawler step of the
pyPegaArchiver job.) The record is pending to go through the Copier step of the pyPegaArchiver job. |
| Archived | 2A. | (Status occurs after the pyPegaArchiver job.)
The record is copied to Pega Cloud File Storage. |
| Archive-External | 2B. | (Status occurs after the pyPegaArchiver job.)
The record is an external attachment, and reference is copied to Pega Cloud File Storage. |
| Archive-Shared | 2C. | (Status occurs after the pyPegaArchiver job.) The record is shared between cases, and may not be eligible for an archival process. |
| Archive-Failed | 2D. | (Status occurs after the pyPegaArchiver job.) The archival process failed. |
| Pending-Purge | 3A. | (Status occurs after the pyPegaIndexer job.) The record has been indexed into Elasticsearch and is pending to go through the purge process. |
| Indexing-Failed | 3B. | (Status occurs after the pyPegaIndexer job.) The indexing of the record into Elasticsearch failed. |
| The pr_metadata table is empty. | 4. | (The pyPegaPurger job deletes all entries in the pr_metadata table after the job succeeds.) The record has been purged from the Pega database. |
Additionally, you can validate that your case archival process succeeded by running a report for cases that are resolved per their archival policy before and after running the archiving process. The difference in reports shows cases that Pega Platform purged from the primary database and copied to Pega Cloud File Storage.
You can review if Pega Platform archived a specific case by searching for archived work items in the Case Management Portal.
For more information, see Reviewing archived case data.
Using logs to troubleshoot your archiving and purge process
If your archival process did not run as expected, you can obtain the log files for troubleshooting.
- Enable the following loggers:
- datastoreexecutor.crawler.CaseCrawler
- datastoreexecutor.Archiver.CaseArchivalStrategy
- datastoreexecutor.databroker.IndexManagerService
- com.pega.platform.datastoreexecutor.purger.internal.PurgerImpl
For more information about viewing logs, see Viewing logs.
- Access your log files.
- Use Kibana to access your log files.
Job Schedulers run on any available node. You can access the logs of your archiving and purge jobs regardless of what node they run on by using Kibana.
For more information, see the article Accessing your server logs using Kibana.
- Optional: If you cannot use Kibana, use activities to run
archive and purge on your local node:
Instead of running the pyPegaArchiver, pyPegaIndexer, pyPegaPurger jobs, run the following activities:
- pzPerformArchive
- pzPerformIndex
- pzPerformPurge
For more information about using activities, see Creating an activity.
The PegaRules log gets created on the node on which you run the activity.
- Use Kibana to access your log files.
Previous topic Managing your case archival process Next topic Configuring archive settings