An example text analyzer in your application
The NLP Sample application includes an example Text Analyzer rule, named FTModels, that you can use to explore text analytics capabilities after you install the NLP Sample, without having to configure any supporting rules. This rule enables sentiment, classification, and entity extraction analysis.
Sentiment analysis
With sentiment analysis, your application can detect and analyze the feelings (attitudes, emotions, opinions) that characterize a unit of text, for example, to find out whether a product review was positive or negative. Knowledge about customers' sentiments can be very important because customers often share their opinions, reactions, and attitudes toward products and services in social media. Additionally, customers are often influenced by opinions that they find online when they make buying decisions.
The FTModels text analyzer references the pySentimentModels decision data rule, which contains JAR binary files with sentiment analysis models for English, Spanish, French, and German languages. The models were trained with the MAXENT machine-learning algorithm to provide a high level of accuracy for sentiment analysis.
Classification analysis
By applying classification analysis, you can assign one or more classes or categories to a text sample to make it easier to manage and sort. Classification analysis can help businesses improve the effectiveness of their customer support services. By classifying customer queries into various categories, the relevant information can be accessed more quickly, which increases the speed of customer support response times.
The NLP Sample application performs classification analysis based on various taxonomies. A taxonomy is a list of predefined categories that the NLP Sample application assigns to text. Categories are assigned on the basis of topics that are defined for each category. If the text analyzer detects a topic from a category in a text sample, then that sample is assigned to that category in the analysis results. In the Pega 7 Platform, taxonomies are part of decision data rules. You can view or modify the default taxonomies by downloading CSV files that contain taxonomies from the corresponding decision data rules. The following table shows simplified examples of categories in the taxonomy for the automobile industry:
| Primary category | Secondary category | Topics |
|---|---|---|
| Features/Interiors | Audio/Entertainment | speaker,antenna,radio,radios,fm,am/fm,xm,sirius,xmradio,bose,dolby,"surround sound",speakers,db,decibel,treble,bass,"sound system",stereo,"audio system", |
| Design and style | Color | color,teal,orange,beige,turquoise,black,white,colour,metallic,silver,brown, gold,pink,hue,hues,red,yellow,green,blue,coral,tint, |
You can use the following default taxonomy decision data rules to classify your content:
- AutomobileTaxonomy - Analyzes text samples that relate to the automobile industry. This rule contains a taxonomy for English only.
- BankingMultiLanguageTaxonomy - Analyzes text samples that relate to banking. This rule contains taxonomies for English, Spanish, German, and French.
- CustomerSupportMultiLangTaxonomy - Analyzes text samples that relate to customer support. This rule contains taxonomies for English, Spanish, German, and French.
- TelecomMultiLangTaxonomy - Analyzes text samples that relate to the telecommunications industry. This rule contains taxonomies for English, Spanish, German, and French. Additionally, the English taxonomy contains a JAR binary file with a MAXENT classification analysis model.
Entity extraction analysis
With entity extraction analysis, you can extract named entities from a text sample and assign them to predefined categories, such as names of organizations, locations, persons, quantities, or values.
To support entity extraction analysis, the FTModels text analyzer references a certain number of default topics, entity extraction models, and entity extraction rules.
Topics are keyword terms and phrases that you want to identify and extract from the text. You can assign a set of synonyms to each topic because the topic can be referred to in multiple ways, depending on the domain. For example, the topic taxi can be associated with such synonyms as cab, taxicab, or ride.
Entity extraction models detect entities whose names are not limited by a certain pattern or a dictionary (for example, names of people, organizations, or places). Entity extraction models operate within the principles of machine learning. The following entity extraction models are available by default:
- pyLocation - Extracts the names of cities, countries, regions, and so on, for example, New York, Great Britain, or Bavaria.
- pyOrganization - Extracts the names of organizations, companies, and so on, for example, Pegasystems, Apple, or Microsoft.
- pyPerson - Extracts the names of people.
- Product - Extracts the names of products, for example, iPhone, Samsung Galaxy, Nokia 1100. This rule is available only for the NLP Sample application.
- Data - Extracts terms that relate to data quantity, for example, 3 GB, 3 gigs, 300 Mbps. This rule is available only for the NLP Sample application.
Entity extraction rules detect entities whose names match a specific pattern or a closed set of dictionary terms (for example, product names or identification numbers). Entity extraction rules are based on Apache Ruta scripts. The following entity extraction rules are available by default:
- pyDate - Extracts dates, according to various patterns, for example, DD/MM/YYYY, the name of a month, followed by a day.
- pyEmail - Extracts email addresses, for example, [email protected].
- pySSN - Extracts social security numbers, for example, 000-456-7890.
- pySalutation - Extracts titles of respect, for example, Mrs, Mr, or Dr.
- Complex - Showcases the complex entity detection by accessing the text analytics pipeline. This rule classifies telecom samples as complex when a sample:
- Contains an entity of type Organization.
- Is classified as belonging to the Account Management > Change Number category.
- Is characterized as having a Negative sentiment.
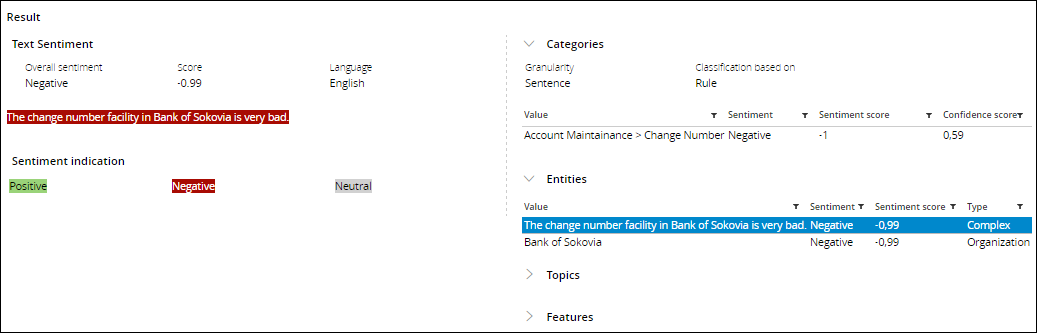
Detection of complex entity rules in NLP Sample