About the Regular Expression tool |
Use the Regular Expression tester to test whether a text pattern matches the regular expression.
5. Complete the detail form.
Field |
Description |
| Regular Expression |
Enter a regular expression to be used, using syntax conforming to the Java implementation of regular expressions |
| Source |
Enter source text to be searched for matches to the regular expression. |
| UNIX Lines |
Select to recognize only newline characters (\n, also called line feed) as end-of-line delimiters. Clear to recognize additional characters or character pairs as end-of-line delimiters: carriage return (\r), carriage return followed by newline, next-line (\u0085), line-separator (\u2028) and paragraph-separator (\u2029). |
| Multilines |
Select to cause the expressions ^ and $ to match immediately after or immediately before, respectively, a line terminator or the end of the input sequence. Clear to have these expressions only match at the beginning and the end of the entire input sequence |
| Canonical Equivalence |
Select to cause two characters to considered to match if, and only if, their full canonical decompositions match. The expression "a\u030A", for example, matches the string "?" when this flag is specified. By default, matching does not take canonical equivalence into account. |
| Comments |
Select to ignore all white space (tabs and spaces) within the Source text, and to ignore all material starting with a comment character # through the end of the line. |
| Dot Matches All |
Select to indicate that a period character is to match any character including a line terminator. Clear to indicate that a period character is to match any character except a line terminator. |
| ASCII Case Insensitive |
Select to match uppercase with lowercase ASCII characters. |
| Unicode Case Insensitive |
Select to match uppercase with lowercase ASCII characters. |
6. Click Test Expression .
7. A table of results lists each match of the regular expression found in the Source text.
This regular expression matches the format of Social Security Numbers in the United States:
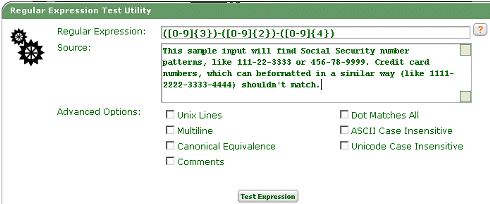
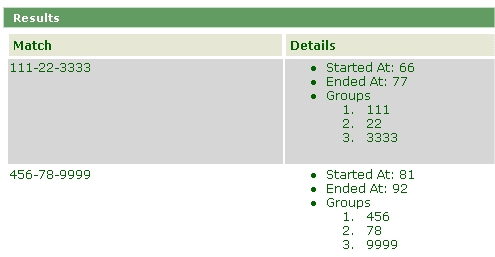

|
free text rules, regular expression |

|
About Transform rules |
 Tools — Other
Tools — Other