Stream service overview
Beginning with Pega Platform™ 7.4, you can use a Stream service to publish and subscribe to streams of data records, store streams of records, and process data in real time. The Stream service is built on the Apache Kafka platform. To understand Kafka-related terminology, see the Apache Kafka documentation.
With the Stream service, you can build real-time streaming data pipelines to move data between systems and applications. You can also build applications that transform and react to streams of data.
Overview
The Stream service ingests, routes, and delivers high volumes of low-latency data such as web clicks, transactions, sensor data, and customer interaction history. Distribution and replication of the stream data records ensure scalability and fault tolerance of the Stream service. The service runs as a cluster on one or more servers. You can spread the servers among multiple data centers to minimize planned or unplanned downtime.
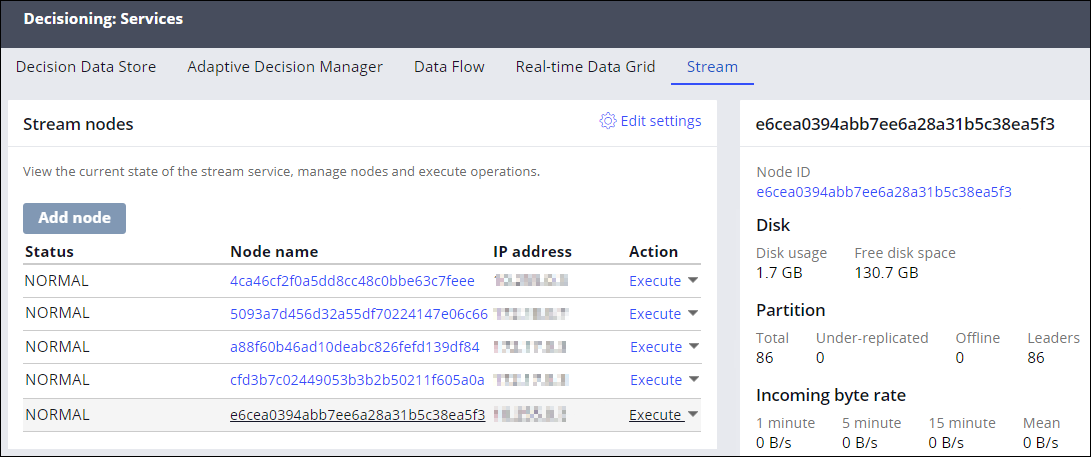 Configuration of the Stream service
Configuration of the Stream service
For more information, see Configuring the Stream service and Stream service node status information.
Deployment configuration
To provide optimal performance of the Stream service, take into consideration the following hardware and software requirements:
- Throughput – Data throughput depends on the number of nodes, bandwidth, CPUs, number of partitions, and the replication factor. The default number of partitions is set to 20 and the replication factor is set to two.
- Memory – The Stream service relies on the file system for storing and caching messages and requires RAM memory to buffer the active readers and writers.
- CPUs – The Stream service requires a modern processor with multiple cores. Selecting a processor with more cores provides extra concurrency and improves the performance of the Stream service.
Disks – Use multiple drives to enhance performance. To ensure optimal latency, do not share the drives that are used for Kafka with other processes, such as collecting application logs. You can configure the Kafka server with multiple log directories that are spread among separate drives.
Required disk space
When preparing disk space for Stream service data, decide how long you want to store the data and allow additional disk space for the internal data that the Stream service produces. By default, the Stream service keeps data for seven days and requires 10% more disk space than the amount that is used by the Stream data.
The Stream service keeps its data in the current working directory, for example, in the <Tomcat_folder>/kafka-data folder for the Apache Tomcatserver. Remember to point the Stream data folder to the location that has sufficient disk space. For more information about how to change the Stream service settings, see Advanced configurations for the Stream service.
In the following example, the Stream service has these requirements:
- Process 1,000 messages per second and store the data for one day.
- Each message is 500 bytes.
- The data is uncompressed.
- The replication factor is set to two.
- The expected throughput is 0.5 MB/s.
During the first minute, the Stream service needs 30 MB of disk space for one copy of the data. With a replication factor of two, the Stream service needs 60 MB during the first minute. During a 24-hour period, the Stream service needs 86.4 GB of disk space, plus 10% of disk space for internal operations. The total minimum disk space for this configuration is 95 GB.
Compression
To save disk space, you can compress data records by using one of the following compression algorithms:
- GZIP – Requires the least bandwidth and disk space, but might cause bandwidth saturation of your network until the maximum throughput is reached.
- LZ4 – Maximizes the performance of the Stream service.
- Snappy – Is faster than GZIP but does not provide high compression, which might limit the throughput of the Stream service.
Multiple data center setup
The Stream service supports multiple data center setup on the level of racks. To use this type of setup for your Stream service, supply the rack information in the prconfig.xml file by adding an entry that is similar to this example:
<env name="dsm/services/stream/server_properties/broker.rack" value="Rack1"/>
Previous topic HDFS and HBase client and server versions supported by Pega Platform Next topic Kafka as a streaming service