Requirements and best practices for creating a taxonomy for rule-based classification analysis
The right classification of data in a taxonomy makes relevant information more accessible, which can have various practical applications. This information can help you address customer support requests in a timely manner or gather feedback on your products.
The natural language processing capabilities of Pega Platform make it possible for you to classify content that is posted on social media (in the form of tweets, posts, comments, messages, and so on) into various categories to make that content easy to sort and manage. One of the many practical applications for text classification is customer support. By classifying customer queries or comments into various categories, the relevant information can be accessed more quickly, which increases the speed of customer support response times. You also can combine classification analysis with sentiment analysis (for example, in product reviews) to examine which product features are commented about the most often and whether the comments are negative, positive, or neutral.
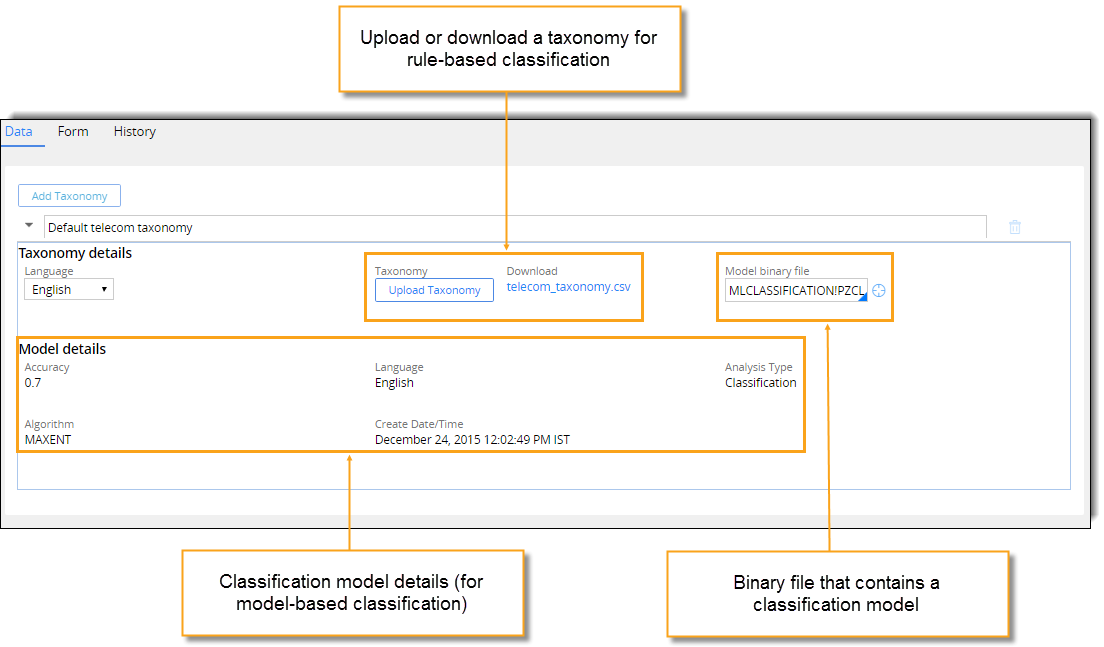
To use a custom taxonomy in your application, define the categories that you want to classify the content into, and then add those categories to a CSV file. Upload that file to your application as part of taxonomy Decision Data rules.
Taxonomy model for rule-based classification
The taxonomies for rule-based text classification are stored in taxonomy decision data rules in CSV files. You can upload or download a taxonomy file to modify it (for example, to add or remove categories). To upload your custom taxonomy into the Pega Platform, the CSV file must contain the following columns:
To extend your category definition with additional levels of subcategories, you can add columns that are named Third and Fourth.
Primary
This column contains the top-level category. If you want to classify text content according to different types of products that you offer, the top-level category can be the product type, for example, Laptop, Phone, TV set, and so on.
Second
This column contains a secondary category that can be derived from the top-level category. Defining this category is optional; the Second column can be empty. Secondary categories can make text classification more granular. For example, you can extend the Laptop category and add secondary categories to it, such as Touchbar, Display, Audio, and so on.
Should words
This column is very important for category assignment. If the text analyzer encounters any of the words or phrases that are in this column, the text analyzer assigns the content to the corresponding category. Include in the Should words column as many words, phrases, and expressions as possible so that the analyzed content is classified correctly. See the following simplified example:
Example of Should words in a taxonomy file
| Primary | Second | Should words | ... | Child match | Node type |
| In-store support | store,office,premises,shop assistant | ... | FALSE | CATEGORY |
Must words
You can narrow down your categorization conditions by specifying the words that the content must contain to be assigned to the corresponding category. You can define multiple Must words for a category, but if the analyzed content does not include any of the words that you defined as Must words, the text analyzer does not assign a category to the content or searches for a different category match within the taxonomy. See the following example:
Example of Must words in a taxonomy file
| Primary | Second | Should words | Must words | ... |
| In-store support | staff,agent,representative,shop assistant | support | ... |
In the preceding example, any piece of content must contain the word support
,
in addition to any of the Should words, to be included in the
Primary column.
And words
This column contains words that are commonly associated with Should words to increase the accuracy and effectiveness with which the text analyzer assigns categories, for example:
Example of And words in a taxonomy file
| Primary | Second | Should words | Must words | And words | ... |
| Support | |||||
| Support | In-store support | staff,agent,representative,shop assistant | support | premises,store,office | ... |
| Support | Phone support | staff,agent,representative,shop assistant | support | phone,call | ... |
In this example, the And words in each category are used by the text analyzer to distinguish between two very similar categories. If you specify any And words in a category, the analyzed text must fulfill the following conditions to be assigned to that category:
- If defined for the category, all Must words must be in the text.
- At least one of the Should words must be in the text.
- At least one And word must be in the text.
If any of these conditions are not met, the text analyzer does not match the category to the analyzed content. Consider the following examples:
The agent in the office offered lots of support.
The text analyzer assigns this content to the In-store support category, because the content contains the Must word (support), a Should word (agent), and an And word (office).I was offered some support during the call.
The text analyzed does not assign the content to any category, because the content does not include a Should word that could be associated with the And word (call).The staff did not support me at all!
The text analyzer does not assign the content to any category, because the content does not include an And word that could modify the Should word to determine the category assignment of the sentence.
Not words
If the text analyzer encounters content with the words or expressions that you entered as Not words, it excludes that content from the text analysis. This solution is useful in the following situations:
- When you are dealing with words that have multiple meanings and you want to
analyze the content that pertains only to a specific meaning of a word. For
example, you analyze tweets about Apple products (for example,
I just bought a brand new Apple laptop and it's great!
), but you want to exclude the tweets that refer to the word apple as a fruit (for example,Working on my new laptop and eating a delicious apple I bought today!
). - When you want to increase the accuracy with which the text analyzer assigns categories by specifying words that the text must not contain to be assigned to the corresponding category (in other words, you configure the text analyzer to not assign a category if the text contains specific words).
In the following example, the words in the Not words column
ensure that content such as The agent in the store didn't give me much
support!
is not assigned to the similar but incorrect Phone support
category.
Example of Not words in a taxonomy file
| Primary | Second | Should words | Must words | And words | Not words | ... |
| Support | ||||||
| Support | In-store support | staff,agent,representative,shop assistant | support | premises,store,office | phone,call | ... |
| Support | Phone support | staff,agent,representative,shop assistant | support | phone,call | premises,store,office | ... |
Child match
Classifies the text in a specific category based on whether the parent category is
matched. When the Child match parameter is set to
TRUE, the text analyzer assigns a secondary category to
the analyzed text only when the primary (parent) category is matched. You can set
this parameter to TRUE when different primary categories have
similar or identical secondary categories, for example:
Example of Child matches in a taxonomy file
| Primary | Second | Should words | Must words | Child match | Node type |
| Phone support | call | TRUE | CATEGORY | ||
| Phone support | Automated system | voice response,prompts,automated,main menu,tree system | TRUE | CATEGORY | |
| Phone support | Live Persons | "call taker",live,human,live operator,real person | TRUE | CATEGORY |
Based on the taxonomy construction in the preceding example, the sentence I just
learned the hard way that the voice response system in uPlusTelco is a
nightmare
will not be assigned to any category by the text analyzer.
Although the sentence meets all the requirements for the Phone Support >
Automated system category category, the sentence does not contain the
Must word (call) that the content is required to contain to be assigned to the
parent category. If the Child match parameter is set to
TRUE, the text analyzer rule first evaluates whether the
content matches the parent category, and then matches the content to any secondary
category, if specified. If the Child match parameter is set
to FALSE, the same sentence is assigned to the Phone
Support > Automated system category because the text analyzer skips the
condition to match the parent category first.
Node type
The values in this column indicate whether a row is a category or not. For all rows that contain categories in your taxonomy, the Node type column must have the value CATEGORY in it.
Best practices for creating a taxonomy
Refer to the following guidelines to create a well-developed and efficient taxonomy that can help you to consistently and accurately classify the content that you extract from social media content.
Create an exhaustive list of categories
A taxonomy must include all possible categories that pertain to the subject of interest to make sure that all the content that you track with your social media data set is categorized correctly. For example, a well-constructed taxonomy for text analysis of reviews of one of your products (for example, a laptop) must contain categories for all key features of that product (for example, processor, display, memory, hard drive, peripherals, and so on).
Test your taxonomy
Perform multiple tests to discover whether the text analyzer that references your taxonomy classifies documents (tweets, posts, comments, and so on) as expected. Testing your taxonomy on a large number of samples can help you detect new categories to define or fine-tune the taxonomy to minimize tracking of unexpected content (for example, by adding or removing Should words, Must words, or And words). Continue testing until you are satisfied with the accuracy of your taxonomy.
Maintain your taxonomy regularly
Taxonomies require regular maintenance to remain relevant and up-to-date. Incorporate new content into the existing categories and create new categories (for example, for new products, equipment, functionality, and so on) on a regular basis to ensure that your taxonomy provides the results that you expect.
Previous topic Best practices for creating categorization models Next topic Recognizing user intent