How to use the Pega Autonomic Event Services Enterprise Health console
The Pega® Autonomic Event Services Enterprise Health console provides current enterprise, cluster, and node-level monitoring for key system statistics. The monitor uses visual indicators to alert you to abnormal operating conditions that may be hindering performance or threaten a processing failure. The console provides access to diagnostic information by way of reports and current statistics.
The Enterprise Health console provides a view of the enterprise at the following levels:
- Enterprise
- Cluster
- Node
This article describes how to use the console's functions and features at each level to ensure quick recognition and remediation of abnormal operating conditions.
- Enterprise view
- Cluster view
- Summary tab
- Reports tab
- Requestors tab
- Agents tab
- Listeners tab
- Management tab
- Node Health Information
- Indicator threshold settings
- Node view
- Node view tabs
Enter your manager ID and password on the Pega Autonomic Event Services welcome screen and click Log In. Remember that passwords are case-sensitive.
The AES Manager Portal displays the Enterprise Health home view (the other navigation bars — Action Items, Reporting, and Administration — are not shown in the image below).

 to go to views that you have previously opened. You can also click Enterprise Health in the navigation panel to return to the enterprise view.
to go to views that you have previously opened. You can also click Enterprise Health in the navigation panel to return to the enterprise view.Enterprise view
The top view of the Enterprise Health console displays a list of clusters comprising the enterprise. The Prod Level column shows the cluster's production level (the level set in the System data instance). The Nodes (Up/Total) column contains a count of active (up) and total monitored nodes in the cluster.
Health indicators
A row displays color-coded indicators showing the collective health of the cluster's nodes. These indicators include:
- Requestors — Number of active requestors
- Agents — Number of agents running
- Memory — Percentage of JVM memory being used
- Pulse — Last time of system pulse
- CPU — Process CPU usage
- Database — Number of database connections, or the occurrence of SQL exceptions
- Cache — Rule cache enabled (yes/no)
- HTTP Response — Average HTTP (browser or portal requestor) response time (in seconds)
- Urgent Events — Alerts or exceptions that require immediate attention
Each indicator condition (Normal, Warn, or Critical) is defined by a set of threshold values set in a related decision table. You can use controls in the console to modify the thresholds at the enterprise, cluster, or node levels as described in section Indicator Threshold Settings in this article.
An agent named Monitor Health Status updates the indicator status for all nodes across the enterprise every two minutes. The indicators refresh automatically when the agent pulses.
Under normal conditions the indicators are green. However, when a node metric exceeds a threshold, the indicator can turn yellow (Warn condition) or red (Critical condition), depending upon the incoming value. For example, if the CPU usage exceeds 80% (but less than 90%), the CPU indicator turns yellow. If it exceeds 90%, the indicator turns red. Warn and Critical indicators help you quickly detect problems and correct the trouble spots before they worsen into chronic performance issues.
If you are a subscriber to the HealthStatusChange scorecard, you will get an email notification when indicator changes level (for example, the HTTP Response indicator changes from Warn to Critical).
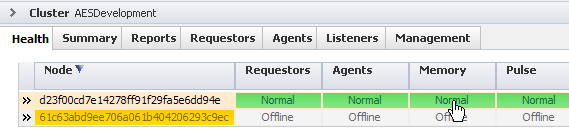
In the example below, the cluster PRPCDevelopment shows that all seven nodes have a normal status for requestor count. However, one node is showing an Agents Critical condition. This indicates that the number of running agents is fewer than the critical threshold of four. In addition, two nodes indicate a Memory Warn condition. This means that more than 80% but less than 90% of total memory is being used.

Use the cluster view to display the conditions of the individual nodes as described in the Cluster View section in this article.
Urgent Events indicator
All health indicators except Urgent Events are constantly updated by way of the Monitor Health Status agent. This functionality provides a steady-state overview of the clusters and nodes across the enterprise.
The Urgent Events indicator, on the other hand, turns red when a critical exception or any of the following alerts occur:
| Alert | Category |
|---|---|
| PEGA0001 - HTTP interaction time exceeds limit | Browser Time |
| PEGA0010 - Agent processing disabled | Agent Disabled |
| PEGA0017 - Cache exceeds limit | Cache Force Reduced |
| PEGA0019 - Long-running requestor detected | Long Requestor Time |
| PEGA0022 - Rule cache has been disabled | Rule Cache Disabled |
| PEGA0027 - Number of rows exceeds database list limit | DB List Row |
| PEGA0035 - A Page List property has a number of elements that exceed a threshold | Clipboard List Size |
These include alerts where KPI or PAL values far exceed their logical limits. Urgent events should be remediated as soon as possible as their impact will seriously degrade system performance. In many cases, these events are related to Critical conditions among the other health indicators.
To investigate the individual events within a node, expand the console as described in the Node View section in this article. Doing so enables you display and open the alerts or exceptions from a list report.
The indicator remains red for 30 minutes from the last Urgent Event, after which it returns to green. If the console has not been monitored by an operator for an extended period, go to node view and open the Urgent Events tab to display an event history.
Subscribers to the HealthStatusChange scorecard will get an email notification when the indicator changes status.
Nodes status indicators
Gray health indicators (Offline or Unknown) appear when one or more monitored nodes in a cluster is not operational. This occurs when the Pega Autonomic Event Services server has not received, within two minutes, a node health message. The Nodes (Up/Total) column uses color indicators to show whether the inactive nodes are shut down as the result of an administrative action or due to an unknown reason such as a communication interruption or system failure. Here is an example:

- When all nodes in a cluster are operational, the cluster's Nodes (Up/Total) value has no color indicator. The health indicators appear as usual.
- When one or more nodes in a cluster are intentionally offline, the Node indicator is yellow. If all nodes are not operational, Offline appears in every health indicator.
- When one or more nodes are shut down due to an unknown reason, the Node indicator is red. If all nodes are non-operational, Unknown appears in every health indicator. Have your system administrator restart the node. If it is running, verify that the monitored node is correctly configured to send health messages. Instructions for making the settings are described in Troubleshooting Pega Autonomic Event Services configuration and installation issues.
- When one or more nodes is not operational (Offline or Unknown) but at least one node is up, the health indicator columns appear as usual.
- When there are Unknown and Offline nodes in a cluster, the Node indicator is red.
In the above example:
- Both nodes in the AESDevelopment cluster are intentionally offline.
- Each node in the AESDevMon and doridsys clusters is shut down for unknown reasons.
- Ten of the 12 nodes in the pega cluster are not operational.
To view a node's operational status at the cluster level, click a Node indicator.
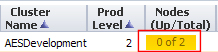
Selecting the AESDevelopment Node indicator shows that both nodes are Offline.

Selecting the Pega Node indicator shows that of the ten non-operational nodes, two are Offline and eight are Unknown (at the Enterprise level, the cluster's node indicator is red).

There are two additional indicators, Disabled and Redirected, which appear when management commands are applied at the cluster or node levels. See Management tab for descriptions.
Removing non-operational node indicators from the console
The system periodically removes nodes displaying Unknown or Offline node status indicators from the console. This occurs when Pega Autonomic Event Services has not detected the node from between 24 hours to 48 hours. If all the nodes in a cluster are not operational, the cluster is removed.
To manually remove a non-operational node, go to the cluster view and click the icon located in the node’s last column.
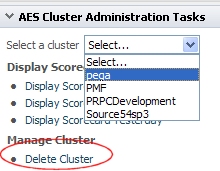
To remove a cluster, open the Administration section, select the cluster from the drop-down list, and click Delete Cluster.
Cluster view
Click on a cluster name to view cluster-level information. The Health tab displays a list of nodes and their individual indicators. Expand the Cluster header to display cluster names, description, production level, and a link to the System Management Application (SMA) URL. In this example, the AES_55SP1 cluster is displayed.

 icon located on the right side of the Cluster section header. If necessary, you can modify the link by clicking Edit to the right of the URL address.
icon located on the right side of the Cluster section header. If necessary, you can modify the link by clicking Edit to the right of the URL address.The cluster view contains tabs for accessing system reports for the cluster and current (runtime) operating statistics for all the nodes within the cluster. The Monitor Health Status agent refreshes the statuses of the various indicators for the various nodes. The tabs are described in the following sections.
Summary tab
Displays a summary snapshot of the cluster's operational status including up time and counts for active requestors, agents, listeners, and database connections. To update the statistics, click the  icon.
icon.

Reports tab
Displays three interactive charts showing cluster-level system statistics for a given date or date range. The charts provide the following controls:
- Use the slider control to adjust the date range:

- Use the slider control to adjust the date range:
- Hover over a vertical line (date) to display an exact count.
- Click the
 icon to present the chart in a larger, full-screen window.
icon to present the chart in a larger, full-screen window. - Click the
 icon to view the summary view output as numeric data.
icon to view the summary view output as numeric data.
To view and interact with the charts, your workstation web browser must include the Adobe Flash Player 9, a free download is available at ![]() www.adobe.com/products/flashplayer.
www.adobe.com/products/flashplayer.
The charts are as follows:
- Average browser response time — The average processing time (in seconds) for all browser requestors on a given date or date range. This number does not include network time.
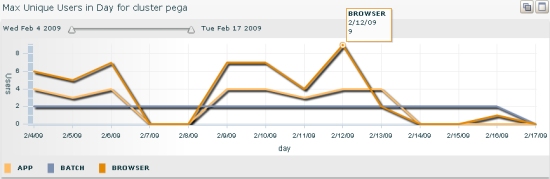
- Maximum unique user in a day — The number of Pega Autonomic Event Services users logged onto the nodes. The users are categorized by the standard requestor types. In this example, there were nine browser requestors on 2/12/09:
- Alerts by category — Alerts received by Pega Autonomic Event Services for the selected cluster. The report displays the name and count in each alert category. Select a row to drill down for more information.
Requestors tab
Displays a list view of requestors currently running in memory on all nodes on all applications. Note the number of nodes running per node. If one node has a much higher number of requestors than other nodes, this can indicate load-balancing issues across the system. Because the node is doing more of the work, users on that node may experience performance issues.
You can perform a search to open a specific node or click Search to open all of them.
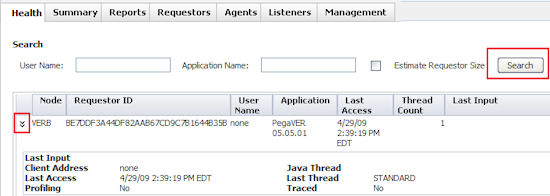
An item displays this information:
- Node — Node name or hex code identifier
- Requestor ID — The unique ID of the requestor. The first character of the name indicates how the requestor is used:
- A is being used by a listener or service rule.
- B is a batch requestor, used by agent processing.
- H is being used by a user (an HTTP interaction).
- P is used for portlet support.
- User Name — The user ID associated with this requestor. None signifies that this requestor is being used by an agent or other process, or that the user is not currently logged in.
- Application — The PRPC application
- Last Access — The date and time the requestor last performed an operation.
- Thread Count — Number of threads associated with this requestor.
- Last Input — The last activity or stream that was executed.
Click on a node's  icon to display additional details, including:
icon to display additional details, including:
- Client Address — The IP address of the machine sending the requestor information. If User Name is none, the client address is a process.
- Profiling — Whether the agent is enabled for this requestor.
- Java Thread — The thread ID of an active requestor, if the requestor is operating in the context of a Java thread. The field can be empty if there is no activity at the time of the snapshot. As one example, SMA on WebSphere runs on a SOAP connector, and in that case the thread number in the SOAP connector thread pool is shown in this column.
- Last Thread — Name of the last thread running
- Traced — Whether Tracer is enabled for this requestor.
Select a requestor on the list and right-click to display a drop-down list of commands.
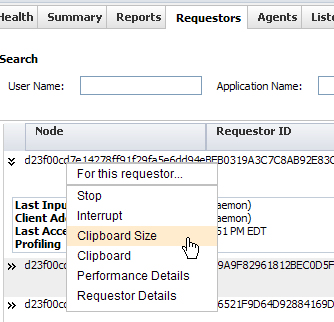
- Stop — Stops the requestor, removes it from the requestor status display, and deletes it from the system.
- Interrupt — Stops the processing of the selected requestor at the beginning of the next activity step. If the requestor is in an error condition, such as executing a Java block that is in a loop, this command may be unable to stop the requestor.
- Clipboard Size — Displays the estimated data size (KB) of requestor and all threads.
- Clipboard — Displays the data on the Clipboard for the selected requestor. If the default security properties file is still in effect, clipboard access is denied with a message like:
Access to the MBean operation/attribute RequestorManagement.Clipboard[java.lang.String]
For more information about the Clipboard, see Data Structures.
has been denied. If you believe that you should have access to this operation or attribute, please check your MBean security settings or contact your System Administrator. - Performance Details — Displays PAL statistics for the selected requestor. See Overview of the Performance Tools (PAL) for information about the statistics.
- Requestor Details — Displays a Trace Entry that shows trace lines for the operations performed by the selected requestor. This is a snapshot display that does not update in real time. Access to the Trace Entry is denied if the default security properties file is still in effect, as noted above for the Clipboard.
Locked requestors
To display a java stack trace of the last accessed thread that locked a requestor, select it in the list.

Right-click and select Requestor Details. Here is an example:

An infinite loop or a request made to a database or external system that is failed, disconnected, or unavailable can cause an abnormally long locking condition. As a result, the node does not receive a response from that external system within the time limit. This may generate a PEGA0019 alert, or trigger a Critical CPU indicator condition.
Agents tab
Displays the agents configured for the nodes comprising the cluster. Each agent item shows the following:
- Node — The node on which the agent is running .
- Enabled — Shows whether the agent is running (a green checkmark) or not (a red ‘x’).
- Ruleset — The name of the agent’s ruleset
- # — The index number of the Agent Activity entry as listed in the Rule-Agent-Queue. Numbering starts with 0.
- Description — Short description of the agent, which can include the Agent Activity class and name.
- Scheduling — Displays either the current wakeup interval for the agent, in milliseconds (for a periodic agent), or the description of settings chosen for the next time the Agent Activity runs, which can be a string like daily, weekdays only (for a recurring agent).
- Last run start — The start time of the last run for this Agent Activity.
- Last run finish — The end time of the last run for this Agent Activity.
- Next run time — The next time this Agent Activity is scheduled to run.
- Exception information — A warning icon appears under the Exception column (see image below) when an agent has stopped running due to an exception. Expand the item to display the message.

A Critical condition with a description of All Agents Disabled indicates that the agent enable setting in the node's prconfig.xml file has been disabled (set to false). Although the Agent and Pulse indicators will indicate Critical, an alert or exception will not be triggered. Consult your application administrator for more information.

Right-click on a row to show a list of commands you can use with the agent. They are categorized for a single activity and for all activities in the queue. Click Query Rulesets to open in a separate browser a list of ruleset names associated with the agent.
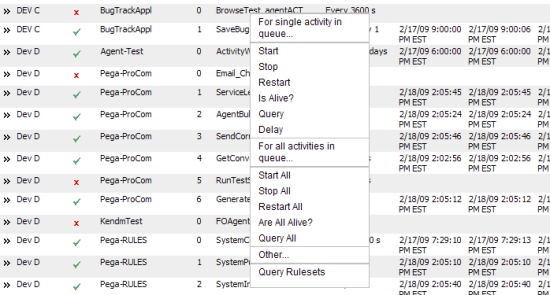
For a single activity in queue
These commands operate on a single agent activity:
- Start — Starts the selected agent activity.
- Stop — Stops an agent activity that is currently running; sets the Enabled column to false, and prints an exception in the Exception section.
- Restart — Stops the selected agent activity and then restarts it.
- Is Alive? — Shows the RuleSet name, queue number, and enabled status (true or false) for the selected agent activity.
- Query — Displays information on the selected agent activity.
- Delay — Delays the next start of this activity to permit Tracer startup. The execution of an Agent Activity can go by too fast to enable the Tracer. This button sets the Agent Activity’s status to waiting. When the Tracer is enabled, the activity can be started.
For all activities in queue
The commands in this section work the same as the For single activity in queue commands, operating on all activities in a ruleset's queue. Selecting any single activity in effect selects all activities for that ruleset queue.
- Start All — Starts all agent activities in a ruleset queue.
- Stop All — Stops all agent activities in a queue or ruleset that are currently running; for each activity in the ruleset, sets the Enabled column to false, and prints an exception in the Exception section.
- Restart All — Stops and then restarts all agent activities in a queue or ruleset.
- Are All Alive? — Shows for a selected agent activity whether all queued agent activities for that ruleset are enabled or disabled.
- Query All — Displays information on all agent activities in a queue or ruleset.
Listeners tab
This tab contains a list of active listeners for all nodes comprising the cluster. Expand an item in the list to display its details including the time started and the Listener class.
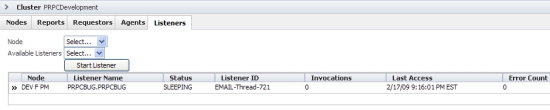
To start a listener, select a node and an available listener in the drop-down menus and click. It will appear in the list after it has been started.
RIght-click on a row to display a list of commands you can use with this listener, this listener type, or all listeners running on the node.
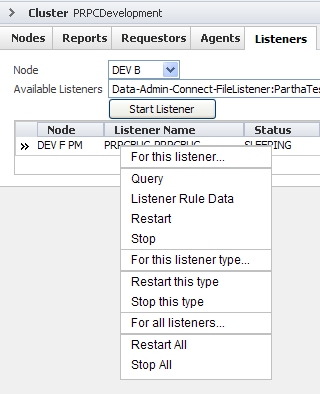
For this listener
- Query — Displays information about the selected listener.
- Listener Rule Data — Data provided about this listener from the Data-Admin-Connect instance.
- Restart — Stops and then restarts the selected listener.
- Stop — Stops the selected listener and removes it from the active listener list.
For this listener type
These commands affect all listeners of the same type as the selected listener in the For this listener section. The types include Email, File, JMS, JMSMDB, and MQ.
- RestartType — Stops and then restarts all listeners of the specified type.
- StopType — Stops all listeners of the specified type.
For all listeners
These commands affect all listeners in the Running Listeners section. It is not necessary to select a specific listener in order to use them.
- RestartAll — Restarts all listeners on this node.
- StopAll — Stops all listeners on this node.
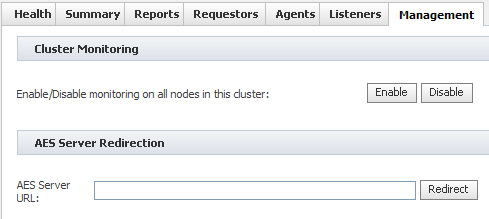
Management tab
As of Pega Autonomic Event Services 3.3.1, this tab appears in the AESManager and AESDeveloper portals. It does not appear in the AESUser portal.
When you use the prremoteutil utility to configure nodes and clusters, then by default:
- Monitoring is enabled when the node starts.
- Alerts and exceptions are broadcast to the Pega Autonomic Event Services server that you specify.
The commands in this tab allow you to dynamically change these settings without having to shut down the cluster and repeat the configuration process.
You can also perform these commands at the node level. See the Management tab topic in Node view tabs.
Before you use these commands, verify the following:
- All clusters and the nodes comprising them are operational.
- All nodes have been upgraded to Pega Autonomic Event Services 3.3.1 or later.
- The target server is operational if you are redirecting clusters or nodes to it.
Use the commands as follows:
Cluster Monitoring — Click Disable to stop monitoring this Pega Autonomic Event Services server for this cluster. Alerts and exceptions are logged on the nodes but are not sent to the server. Health messages are not sent. The health indicators display Disabled as of the next node health pulse. This has no effect on the Node (Up/Total) color indicator. For instance, when a cluster is disabled, the indicator does not turn red. Click Enable to start monitoring again.
Use case: As you build a multi-cluster system, you do not want to receive alerts from individual clusters until the entire system is complete. To do this, you disable the cluster after the nodes are configured and re-enable it (and the other clusters) when the system is ready for service.
AES Server Redirection — To disable monitoring on this Pega Autonomic Event Services server for this cluster and redirect and enable monitoring on another Pega Autonomic Event Services server, enter the target server URL (Pega Autonomic Event Services SOAP servlet URL) in the New AES URL field and click .
Alerts and exceptions are reported to the new server immediately. The cluster appears on the new server's Enterprise Health console as of the next health indicator pulse. The health indicators display Redirected on the original server as of the next node health pulse. This has no effect on the Node (Up/Total) color indicator.
The target server can be running any Pega Autonomic Event Services version. However, the Management tab commands on the target server will not be available unless it is upgraded to Pega Autonomic Event Services 3.3.1 or later.
A group of clusters is deployed on a UAT system, which is monitored by a dedicated Pega Autonomic Event Services server. When UAT is complete, you want to deploy the clusters to a production system, which is monitored by its own AES server. Rather than having to manually re-configure these nodes, you can redirect the clusters from the UAT server to the production server.
When a node is configured for Pega Autonomic Event Services, the Enable / Disable and Redirect commands may be turned off. The node is monitored and appears on the console but the commands cannot be applied to it. For more information, see Autonomic Event Services (AES) 7.2 Monitored Node Configuration Guide.
Node Health Information
From the cluster view, you can expand each node row (using the icon) to display the Node Health Information panel. It is organized into two functional areas as shown below:
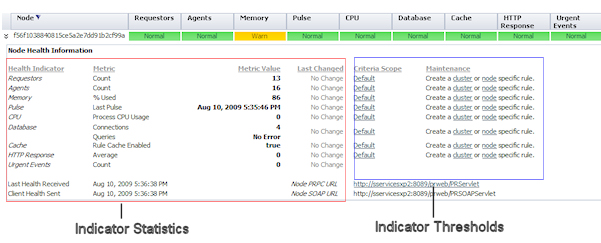
Indicator statistics
To help you monitor the health status of each indicator, the left area displays the following information:
- Health Indicator — The name of the indicator
- Metric — The indicator value's unit of measure
- Metric Value — Indicator value generated by the node as of the last health agent pulse (Last Pulse). When received, the system evaluates this value against its threshold setting. If the value changes the status, the indicator automatically changes color. Use the refresh icon to display the most current statistics in the panel.
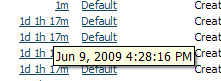
- Last Changed — The time that has elapsed since the indicator changed status. The value will be No Change if there have been no changes since the node was started. To see when the change occurred, hover over a value to display the date and time as shown in this example:
Click on the value to open an indicator history report. Here is an example of an Agents report:
Expand an item to display its details. Both of the items are expanded here: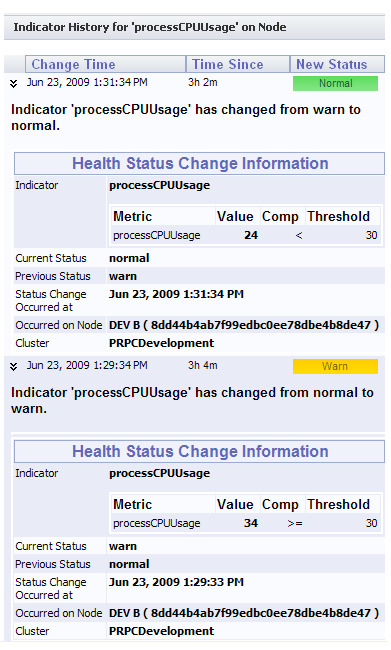
The Warn item'sIndicator section shows that the CPU usage value (34) exceeded the threshold (30). As of the pulse timestamp in the Status Change Occurred at row, the status changed back to Normal when the value fell below the threshold. The Occurred on Node row displays the node name (if any) and the hex code identifier in parentheses.
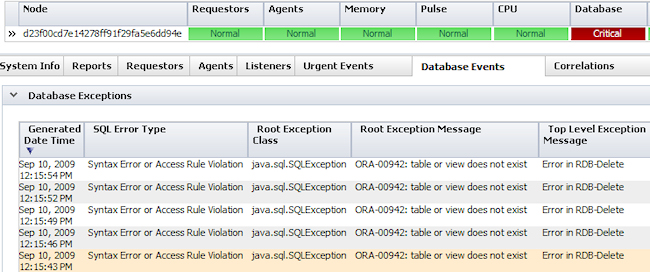
About the database change indicator
The database indicator status changes to Warn or Critical if either of the following is true:
- The total number of database connections exceeds a threshold value
- An SQL exception occurs. The indicator is No Error if the last operation was successful.
Open the Database Events tab (Node view) to display a list of the events that tripped the indicator. Click on an item to for more information. If there were no database exceptions in the past 30 minutes, the list is cleared by the system.
These events also trip the Urgent Events indicator and appear in the Exceptions report on the Urgent Events tab.
Indicator threshold settings
It is advised that you do not modify the default health indicator thresholds, which are set to levels that fully utilize available resources and optimize system performance. If necessary, you can modify threshold values under the Criteria Scope and Maintenance columns as described in this section.
Criteria Scope — Indicates the specificity of the criteria being used to evaluate the indicator on a monitored node. A decision table is used to define the logic for evaluating the statistic values against their criteria. The Default tables contain criteria that are applied to all nodes across the enterprise. To open the decision table, click the Default link next to the health statistic name. Here is the default table used for the Requestors statistic. The values apply to all clusters in the enterprise.
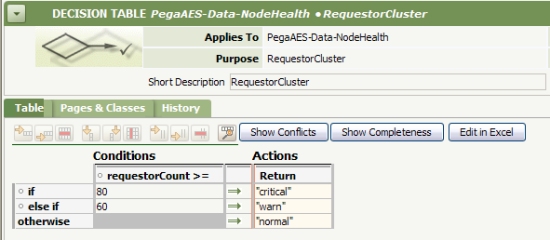
You can modify the values and save the rule. Doing so updates all the criteria values for all Requestors throughout the enterprise.
Maintenance — Provides cluster or node level overrides for the default indicator logic. Clicking on one of these links creates a circumstanced version, which overrides the default table. There are two override links:
- Cluster - The criteria is defined for a cluster (overriding criteria defined for the enterprise scope).
- Node - The criteria is defined for a node (overriding criteria defined for both the cluster and the enterprise scopes)
For example, if you want to change the default Requestors criteria only at the cluster level, do the following:
- Click the cluster link under the Maintenance column on the Requestor row.
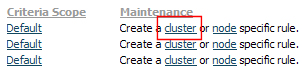
Pega Autonomic Event Services creates a new circumstanced instance of the default requestor table. The circumstance is defined by the cluster to which the node belongs.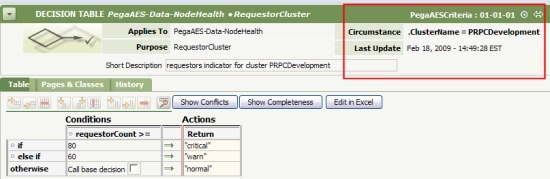
- You can either keep the existing values and exit the rule form, or you can modify the values and save the rule. When you exit the form, the Criteria Scope and Maintenance columns look like this:
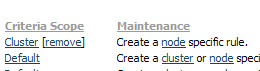
- The values in the Cluster rule apply to all the nodes within the specified cluster (the one to which the node belongs). The above configuration appears when you open any node in this cluster view.
Node view
From within the cluster view, select an indicator (not the expand icon) to open a set of reports and charts associated with the node.
Here is an example of a node view:
Tip: While in cluster view, selecting a Requestor, Agents, Database, or Urgent Events indicator opens the indicator's respective tab. Selecting the HTTP Response indicator does not open a node view.
Expand the Cluster header to display details about the node. It also contains links to the SMA tool (editable) and to the Process Commander application. Use the Cluster link in the top header to return to cluster view at any time.
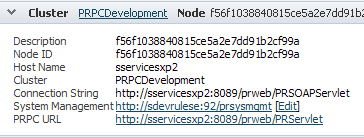
Node-view tabs
The node view contains ten tabs.

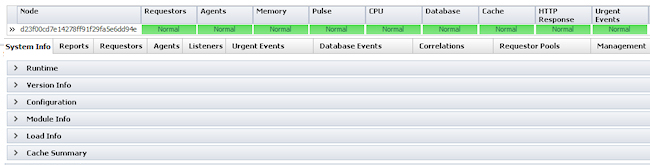
System Info tab — has six expandable sections:
- Runtime — Interactive charts displaying data from the prior two weeks to the most current agent pulse. These include memory used (MB), CPU used (percentage), and number of active requestors (by type).
- Version Info — Displays node, build, and JVM information, and a count of system-wide requestor starts (by type).
- Configuration — Displays the contents of the monitored node's prconfig.xml file.
- Module Info — Displays versions for all currently loaded java classes that make up the Process Commander rules engine. This is useful troubleshooting information where you need to determine whether a particular hot fix was applied to a Process Commander system.
- Load Info — Displays four interactive charts showing node load trends. Charts include average browser response time, average compilation (CPU) time for all the assembled classes, compilation count, and assembly count.
- Cache Summary — Displays in real time an interactive chart showing the sizes (in megabytes) of the FUA and Rule caches.
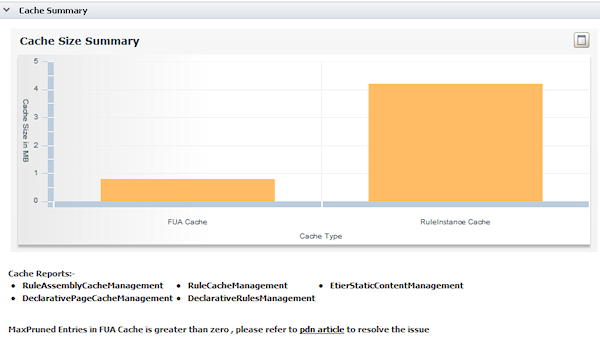
For a detailed report about each cache, click a link located under the chart.
A link to the article Understanding the PEGA0017 alert - Cache exceeds limit appears when the Max Pruned value in these caches is greater than 0.
FUA Cache — The Max Pruned value in FUA Alias Entries (Max Pruned in Assembled Class Entries is not used as a threshold).
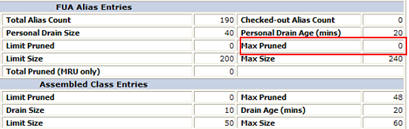
Rule Instance Cache — The Max Pruned values in either Instance MRU or Rule Resolution Alias MRU caches.

When the Cache Size reaches its Max Size ( about 125% the Limit value), there is no physical space to increase cache size. The system prunes the entries and Max Pruned shows a non-zero value. This condition is serious as it is likely to cause erroneous processing behavior.
Reports, Requestors, Agents, and Listeners tabs — provide, at the node level, information as described previously for the cluster-level tabs.
The Urgent Events tab contains two lists of events (alerts and exceptions) that triggered the indicator (only Alerts shown in the example below).
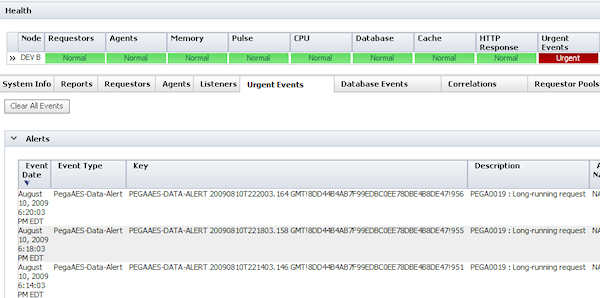
When an event occurs, the item is appended to the list. Click on an item to open it. Items remain in the list indefinitely. To remove all of them, click .
Database Events tab — Displays a list of the SQL exceptions that tripped a Warn or Critical Database indicator. Click on an exception for more information. The list remains in the tab for thirty minutes and is then cleared by the system. These events also trip the Urgent Events indicator and are reported in the Urgent Events tab.
Correlations tab — Provides links to alerts reports or to other tabs that are related to Critical indicators (Requestors are not included). The links are grouped by indicator. For example, if the Memory indicator is critical, open the Correlations tab and select each of the links in the Memory group. Note that some changes to a health indicator do not necessarily produce correlated alerts. For example, a critical Memory condition is probably related to a PEGA0028 alert, but a PEGA0035 alert may not be correlated to the condition.
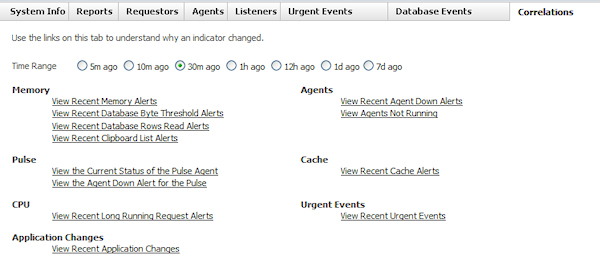
To use this tab, select the time range for the report data you want to display. For example, if you select 1d ago and click View Recent Memory Alerts, the report will include all PEGA0028 alerts generated in the previous 24 hours. The default is thirty minutes. Note that the Time Range setting does not affect the View Agents Not Running or the View the Current Status of the Pulse Agent correlations. The links in the indicator groups are as follows:
- Memory — Displays lists of PEGA0028, PEGA0004, PEGA0027, and PEGA0035 alerts.
- Pulse — Opens the Agents tab, which displays a list of the running agents. Displays a list of PEGA0010 alerts.
- CPU — Displays a list of PEGA0019 alerts.
- Agents — Opens the Agents tab, which displays a list of the agents that are disabled. Displays a list of PEGA0010 alerts.
- Cache — Displays a list of PEGA0022 alerts.
- Urgent Events — Opens the Urgent Events tab, which lists the events that occurred within the specified time range.
Click on an item in an alerts report to display the form. Open the related action item by selecting Click to find related work in the Related Work section.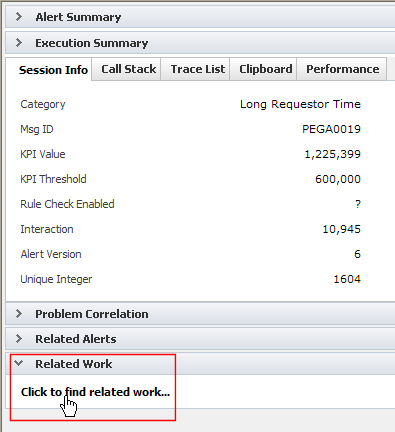
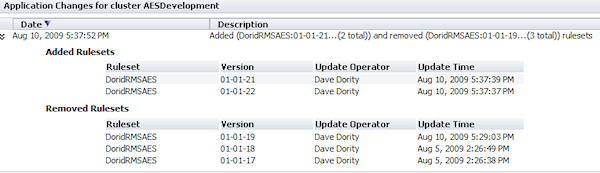
- Application Changes — Displays a list of ruleset versions that have been added or deleted from the cluster (to which the node belongs). The list also includes the operator and time an update was made. A Pega Autonomic Event Services agent checks the application once every twenty four hours. If there have been updates between two consecutive agent pulses, the system adds entries to the list. If no updates have occurred, there are no entries. Here is an example of a report entry made on August 10, 2009 (the date and time in the header indicate when the last pulse occurred):
Requestor Pools tab — Contains statistics for a set of idle and active requestors that PRPC reserves for use by the services in a service package.
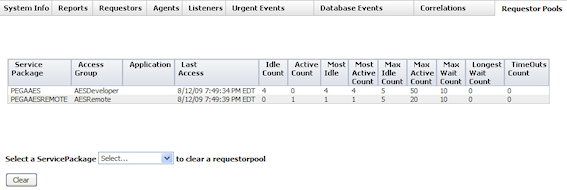
When an active requestor completes processing, PRPC checks the limit for idle requestors before returning that requestor to the pool. If the pool is under the limit, the requestor becomes idle and PRPC returns it to the pool. If the pool is at the limit, PRPC deletes the requestor. To delete an idle requestor, select it in the ServicePackage drop-down and click .
Management tab — Contains commands to:
- Turn monitoring off or on for this node on this Pega Autonomic Event Services server.
- Redirect monitoring for this node on this Pega Autonomic Event Services server to another.
For descriptions of the commands, see the Management tab section in this article.
Previous topic Introduction to Pega Autonomic Event Services Next topic How to use charts and reports in Pega Autonomic Event Services